GenAI Engineer Thailand #0 - Self-hosted LLM on GCP


ผ่านไปแล้วสำหรับอีเวนต์แรกของ GenAI Engineer Thailand (Discord group) กลุ่มนี้เกิดขึ้นเพราะพวกเราอยากให้มันเป็นที่รวมตัวของ practitioner ทั้งหลาย ได้มาแชร์ประสบการณ์กัน ที่สำคัญคือได้แลกเปลี่ยนความรู้กัน เอาเทคนิคไอเดียเด็ด ๆ มาแชร์แบ่งปันให้กันฟัง จะได้เอาไปต่อยอดใช้ในงานจริงได้ด้วย 😉
ในอีเวนต์นี้ เรามี speaker สุดพิเศษ คือคุณ Coco - Senior AI/ML Engineer จาก ArcFusion.ai มาแชร์เรื่องการ Deploy LLM บน GCP ให้ฟังกัน🌟
ในบทความนี้ ผมสรุปมาให้สำหรับใครที่พลาดไปนะฮะ
เมื่อวาน มีโอกาสได้ จัด event knowledge sharing เล็กๆ เกี่ยวกับ GenAI ฮะ
— lukkiddd 🧮 (@lukkiddd) May 18, 2024
Event แรกพี่ Coco มาแชร์ เกี่ยวกับ Self Hosted LLM ด้วย vLLM
ใครอยากอ่านสรุป กดตามลิ้งไปได้เลยฮะ 🤗https://t.co/g2YYxC8ThR
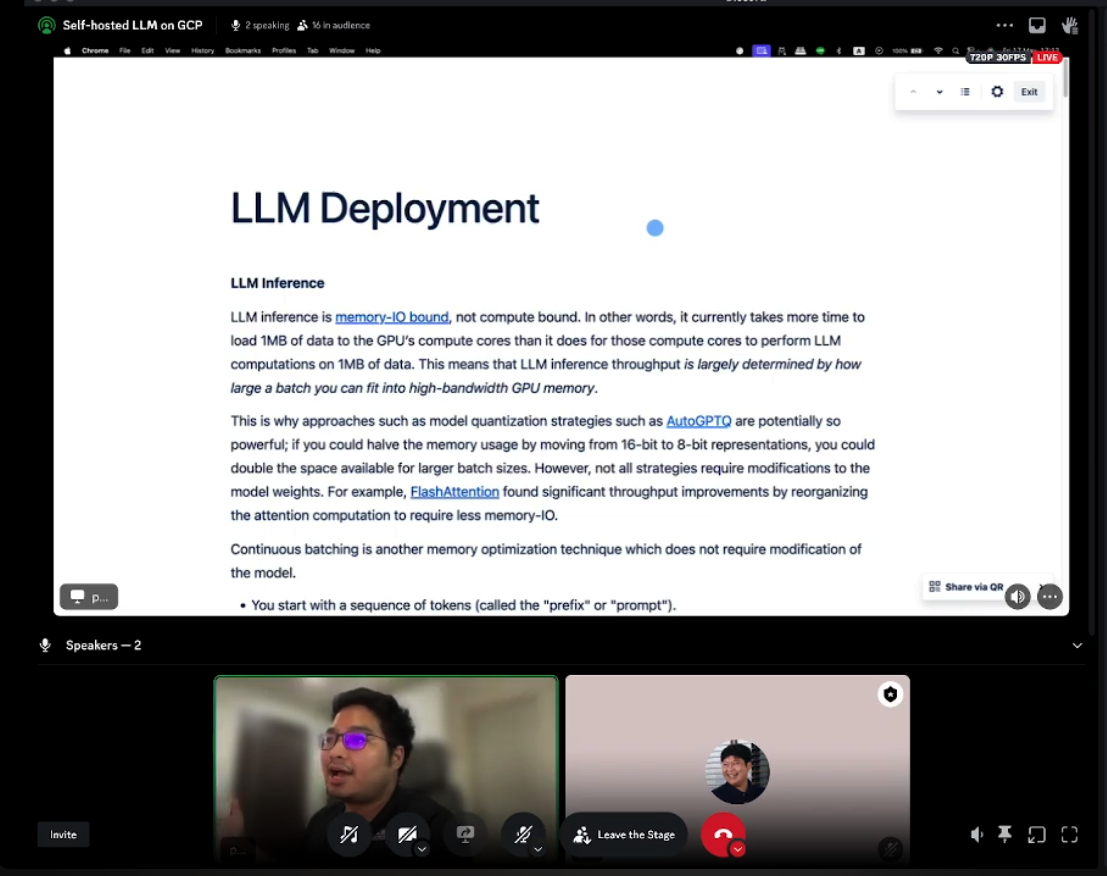
LLM is memory-bound
คุณ Coco บอกว่า การทำ Inference ของ LLM นั้นเป็นแบบ Memory-bound ไม่ใช่ Compute-bound นั่นหมายความว่า การโหลดข้อมูลเข้าไปใน GPU Memory ใช้เวลานานกว่าการประมวลผลข้อมูลซะอีก 😱 ดังนั้น Bottleneck หลักๆ คือขนาดโมเดล/prompt ที่ยัดเข้าไปใน GPU Memory ได้นั่นเอง
เราจะได้รู้ได้ยังไงว่า เป็น Compute-Bound หรือ Memory-Bound
เราต้องคำนวนหา Operation per byte (ops:byte) ออกมาก่อนฮะ
- ถ้างานที่เราทำน้อยกว่า ops:byte ของ hardware แปลว่า เป็น memory-bound
- แต่ถ้ามากกว่าก็เป็น compute-bound
คำนวน ops:byte ยังไง?
- ops/byte = compute_bandwidth / memory_bandwidth
เช่น Nvidia A10 มี compute_bandwidth (FP16 tensor core) = 125 TFLOPS และ GPU memory bandwidth อยู่ที่ 600 GB/s
นั่นแปลว่า
- 125 TF / 600 GB/s
- = 208.3 ops / bytes
Reference: https://www.baseten.co/blog/llm-transformer-inference-guide/
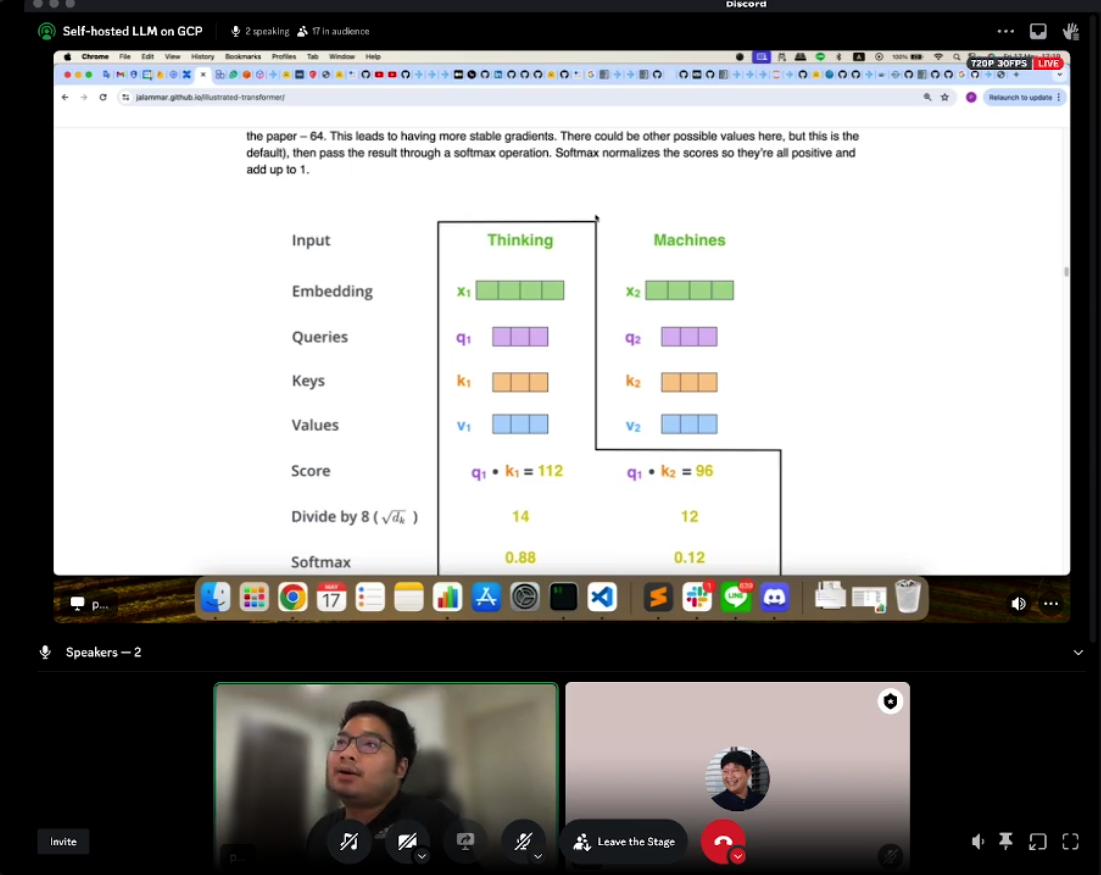
แล้วเราจะรู้ได้ยังไงว่า LLM ต้องใช้ กี่ ops:byte?
เราต้องหาจุดที่มีคำนวนเยอะที่สุดใน model ซึ่ง โดนส่วนใหญ่คือ ช่วง Attention Layers
https://www.baseten.co/blog/llm-transformer-inference-guide/
จากตัวอย่างในลิ้งข้างบน Llama2 7B จะมี 62 ops/byte
ถ้าเทียบกับการเอามารันบน A10 ก็จะเห็นว่า 62 ops/byte น้อยกว่า 208.3 ops/byte นั่นแปลว่า Llama2 7B จะติด memory bound
Quantization and Memory Optimization
ดังนั้นยิ่งเราจัดการ memory ได้ดีเท่าไหร่ก็จะสามารถเพิ่มความเร็วในการทำ Inference ได้ดีเช่นกัน เทคนิคที่คุณ Coco พูดถึงนั้น เช่น
- Quantization อย่าง AutoGPTQ, AWQ ที่ช่วยบีบอัดขนาดการเก็บข้อมูลให้เล็กลง 📉
- FlashAttention ที่ปรับแต่ง Attention Mechanism ใหม่ให้ไวขึ้น ⚡️
- Continuous Batching - Batching คือการรวบ (Batch) request ที่ขอเข้ามาเป็นก้อนเดียว แล้วรันพร้อมกัน ทำให้ไม่ต้องต่อคิว พร้อมกับคำว่า Continuous ทำให้ ไม่ต้องรอให้ batch ครบ ก็ประมวลได้เลย ลองจินตนาการแบบนี้ฮะ
- เวลาเราขึ้นรถตู้ ถ้าเป็น static batching คือ เรารอขึ้นรถตู้ทีละคน รถตู้ก็จะออกตามเวลา หรือเมื่อเต็ม
- ส่วน continuous batching คือ สมมติเรามีรถตู้ 3 คัน คิวรถตู้ก็จะดูว่าคันไหนว่างแล้วบอกเราว่า “ไอหนูไปขึ้นคันนั้นลูก” แล้วออกเลย
- ข้อดีคือ ”ไอหนู“ ก็ไม่ต้องรอ คันไหนว่างก็ขึ้นแล้ว let's go!
Ray Serve and vLLM
อีกอย่างที่ห้ามพลาดเลยก็คือ Framework อย่าง Ray Serve และ vLLM ครับ
- Ray Serve เป็นตัวช่วยในการจัดการทรัพยากรสำหรับ ML ของเรา จะ scale เพิ่มลด cpu/gpu อะไรก็แก้ config ใช้ได้เลย
- ส่วน vLLM ก็เป็น Inference Engine ที่ออกแบบมาสำหรับ LLM โดยเฉพาะ ตัว vLLM นี่คือจะ optimize memory ขั้นสุด ด้วยเทคนิคต่าง ๆ เช่น PagedAttention ทำให้โมเดลใหญ่ๆ ที่ต้องใช้ RAM เยอะ ก็รันได้อย่างไหลลื่น
- ที่น่าสนใจไปอีกคือ vLLM มี Ray integrate มาให้แล้ว ดังนั้นกดรันได้เลยจ้า สบายตัว

Demonstration step-by-step
คุณ Coco ก็มา demo ให้เราดูครับว่า ถ้าเราจะรัน inference server ด้วย Ray และ vLLM เนี่ย step-by-step เลยมันทำยังไงบ้าง ตามไปดูกันฮะ
เพิ่มเติ่มเรื่อง Ray จากคุณเสือ (Tora) ครับ
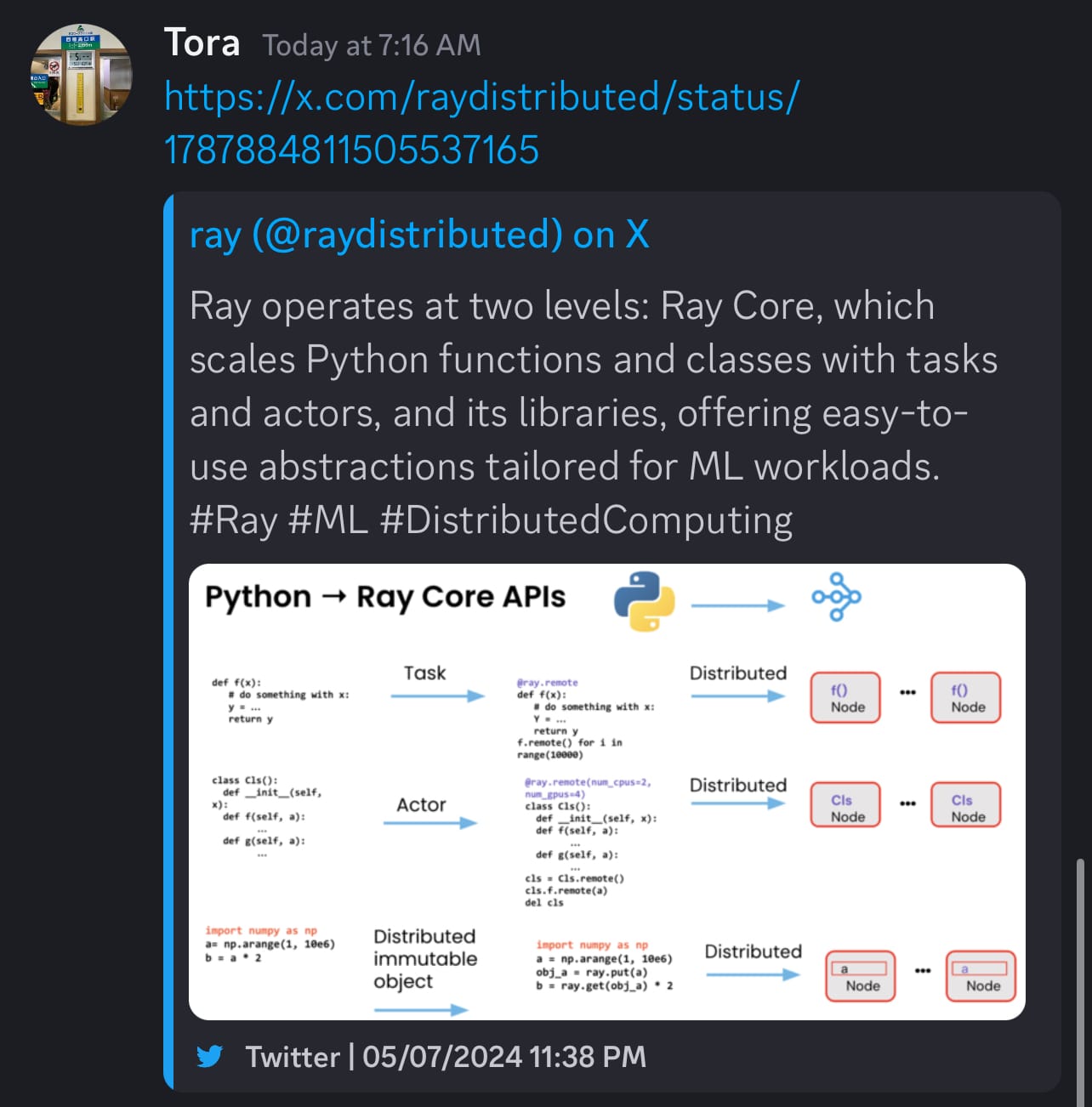
Ray operates at two levels: Ray Core, which scales Python functions and classes with tasks and actors, and its libraries, offering easy-to-use abstractions tailored for ML workloads. #Ray #ML #DistributedComputing pic.twitter.com/tEaSMGkFgg
— ray (@raydistributed) May 7, 2024
Conclusion
สุดท้ายนี้ ขอขอบคุณทุกคนมากนะครับ ทั้งที่อ่าน และที่ฟังใน Live Session หวังว่าความรู้ดีๆ จากคุณ Coco จะเป็นประโยชน์กับเพื่อนๆ LLM practitioner ทุกคนนะครับ ขอบคุณที่อ่านกันมาถึงตรงนี้เลย Happy Deploying! 😉👍
Additional resources
บทความที่น่าสนใจฮะจากคุณ Natthanan Bhukan (MLE at CJ Express) เขียนอธิบายว่า vLLM ทำยังไงถึงรัน LLM ได้เร็ว
