ลด Cost LLM ยังไงได้บ้าง?
ลดต้นทุน LLM: ใช้โมเดลเล็ก, บีบ Prompt, สรุปบทสนทนา, RAG สำหรับข้อมูลใหญ่, Caching, Batch Request, YAML แทน JSON, LLM Router, เข้าใจ framework ลดการเรียก LLM, ตรวจสอบประสิทธิภาพต่อเนื่อง


ยาวเกิ๊น;งั้นอ่านนี่
1. เลือกโมเดลให้เหมาะกับงาน 🎯
อย่าเพิ่งรีบไปใช้โมเดลใหญ่ ๆ เลยนะครับ บางทีโมเดลเล็ก ๆ ที่เทรนมาเฉพาะทางก็ทำงานได้ดีไม่แพ้กัน แถมประหยัดกว่าเยอะ! ลองนึกภาพว่าเราจะใช้รถบรรทุกขนาดใหญ่ไปซื้อของที่ 7-11 มันก็ดูเกินความจำเป็นใช่ไหมล่ะ 😅
2. ประหยัด Token ให้สุด ๆ 💎
Token นี่แหละตัวการสำคัญที่ทำให้เราต้องควักกระเป๋าจ่าย มาดูวิธีประหยัดกัน:
• บีบ prompt ให้สั้นกระชับ แต่ได้ใจความ
• ใช้ YAML แทน JSON ถ้าต้องการ output แบบมีโครงสร้าง (ประหยัดโทเค็นกว่าเยอะ!)
• สรุปบทสนทนายาว ๆ ให้สั้นลง ก่อนส่งต่อให้ LLM
3. ใช้ RAG ช่วยลดการใช้ Token 🔍
RAG หรือ Retrieval Augmented Generation นี่เจ๋งมากครับ แทนที่จะยัดข้อมูลทั้งหมดเข้าไป มันจะเลือกแค่ข้อมูลที่เกี่ยวข้องจริง ๆ มาใช้ ประหยัดโทเค็นไปได้เยอะเลย!
4. ใช้ LLM Router
ใช้ Model มาช่วยเลือกว่าคำถามไหน ควรใช้ LLM ตัวใหญ่ คำถามไหนควรใช้ LLM ตัวเล็ก
5. ลดจำนวนครั้งที่เรียกใช้ LLM 🔄
นี่เป็นเทคนิคที่หลายคนมองข้าม แต่สำคัญมากนะ:
• ใช้ cache เก็บคำตอบที่เคยถามแล้ว
• รวมคำขอหลาย ๆ อันเป็นแบตช์
• ระวัง! บางเฟรมเวิร์คอาจแอบเรียก LLM หลายรอบโดยที่เราไม่รู้ตัว
6. ติดตามและประเมินผลอยู่เสมอ 📊
ราคาของการใช้งาน Large Language Model (LLM) ขึ้นอยู่กับหลายปัจจัย ไม่ว่าจะเป็น use-case ที่นำไปใช้งาน, เรา deploy เองหรือใช้ service provider ถ้าเรา deploy เองก็ต้องคิดค่า infrastructure, GPU, maintenance, engineer ที่คอย optimize LLM เหล่านั้น (เช่น memory usage, latency, concurrency) อีก
ในอีกทางนึง ถ้าหากเราเลือกใช้ service provider เราก็จำเป็นต้องเข้าใจ Pricing model ของแต่ละเจ้าครับ ซึ่งส่วนใหญ่ก็จะคิดราคาตาม ประเภท LLM ที่เราเลือกใช้, จำนวน token ที่เราใช้งาน, และจำนวนครั้งที่เรียกใช้ ตัวแปรเหล่านี้มีผลต่อ Cost ที่เราต้องจ่ายทั้งนั้นครับ มากไปกว่านั้น LLM แต่ละตัวอาจจะใช้ Tokenizer ไม่เหมือนกัน ทำให้จำนวน token ที่ใช้แตกต่างกันในแต่ละโมเดล ซึ่งอาจจะส่งผลถึงภาพรวมของ Cost ที่เราต้องจัดการด้วย
Token อาจหมายถึง คำ, ส่วนของคำ, หรือแม้ตัวอักษรหนึ่งตัว
ใน Blog นี้ ผมจะพาเพื่อน ๆ ไปดูว่า ถ้าเราเลือกใช้ Service Provider เราจะลด Cost ได้ยังไงบ้าง
แต่ก่อนที่เราจะไปถึงเรื่องการลด Cost, อยากจะแนะนำให้เพื่อน ๆ เตรียม evaluation system กันให้พร้อมก่อนครับ เราจะได้ทำการทดลองได้อย่างรวดเร็วและมั่นใจได้ว่าวิธีที่เราใช้ลด Cost นั้น ไม่ส่งผลต่อ Metrics อื่นๆ ที่เราสนใจ เช่น Accuracy, Latency, หรือ Security.
ถ้าพร้อมแล้วเราไปเริ่มกันเลยฮะ! 🚀
It's all about tokens
Tokens อาจหมายถึงคำ, ส่วนของคำ, หรือแม้กระทั่งตัวอักษรหนึ่งตัว ผู้ให้บริการส่วนใหญ่มักคิดราคาจากปริมาณ Token ที่เราใช้ บางเจ้าจะคิดราคาแยกกันระหว่างจำนวน Input Tokens (Prompt) และจำนวน Output Tokens
ยกตัวอย่างเช่น (ณ วันที่เขียน 2024-10-01) GPT 4o mini (gpt-4o-mini) คิดราคาอยู่ที่ $0.15 ต่อหนึ่งล้าน Input Tokens และ $0.60 ต่อหนึ่งล้าน Output Tokens
เพื่อคำนวณจำนวน Tokens ที่ใช้ เราจำเป็นต้องรู้ว่า "Tokenizer" ที่แต่ละโมเดลใช้คืออะไร เพราะ "Tokenizer" แต่ละตัวจะนับ Tokens ด้วยวิธีที่แตกต่างกัน
ยกตัวอย่างเช่น 1.3 Token จะเท่า 1 คำในภาษาอังกฤษ นั่นหมายความว่า หากเรามี prompt ที่ใช้ 750 คำภาษาอังกฤษ จะเท่ากับประมาณ 1,000 Input Tokens
สมมติว่าเรามี task หนึ่งที่ใช้ 250 Input Tokens และตอบกลับมาใช้ 125 Output Tokens หากเราต้องเรียกใช้วันละ 1,000 ครั้ง เท่ากับ 30,000 ครั้งต่อเดือน เราจะได้ตารางราคาเปรียบเทียบตามข้างล่างนี้
Models | gpt-4o-mini | gpt-4o |
|---|---|---|
Input tokens | 250 | 250 |
Input Cost/1M tokens | $0.15 | $5 |
Total Input Cost | $0.0000375 | $0.00125 |
Output Tokens | 125 | 125 |
Output Cost/1M tokens | $0.6 | $15 |
Total Output Cost | $0.000075 | $0.001875 |
Total Cost per call | $0.0001125 | $0.003125 |
Total Cost per month | $3.38 | $93.75 |
Not all tokens made equals
ในแต่ละโมเดล นอกจากจะใช้ Tokenizer ที่แตกต่างกันแล้ว วิธีที่ Tokenizer ตัด Token ของแต่ละภาษายังแตกต่างกันอีกด้วย ตัวอย่างเช่น ในภาษาอังกฤษ หนึ่ง token อาจจะประมาณ 5 ตัวอักษร ในขณะที่ในภาษาไทย หนึ่ง token อาจเท่ากับแค่ 2.5 ตัวอักษร ต่างกันประมาณเท่าตัวเลย
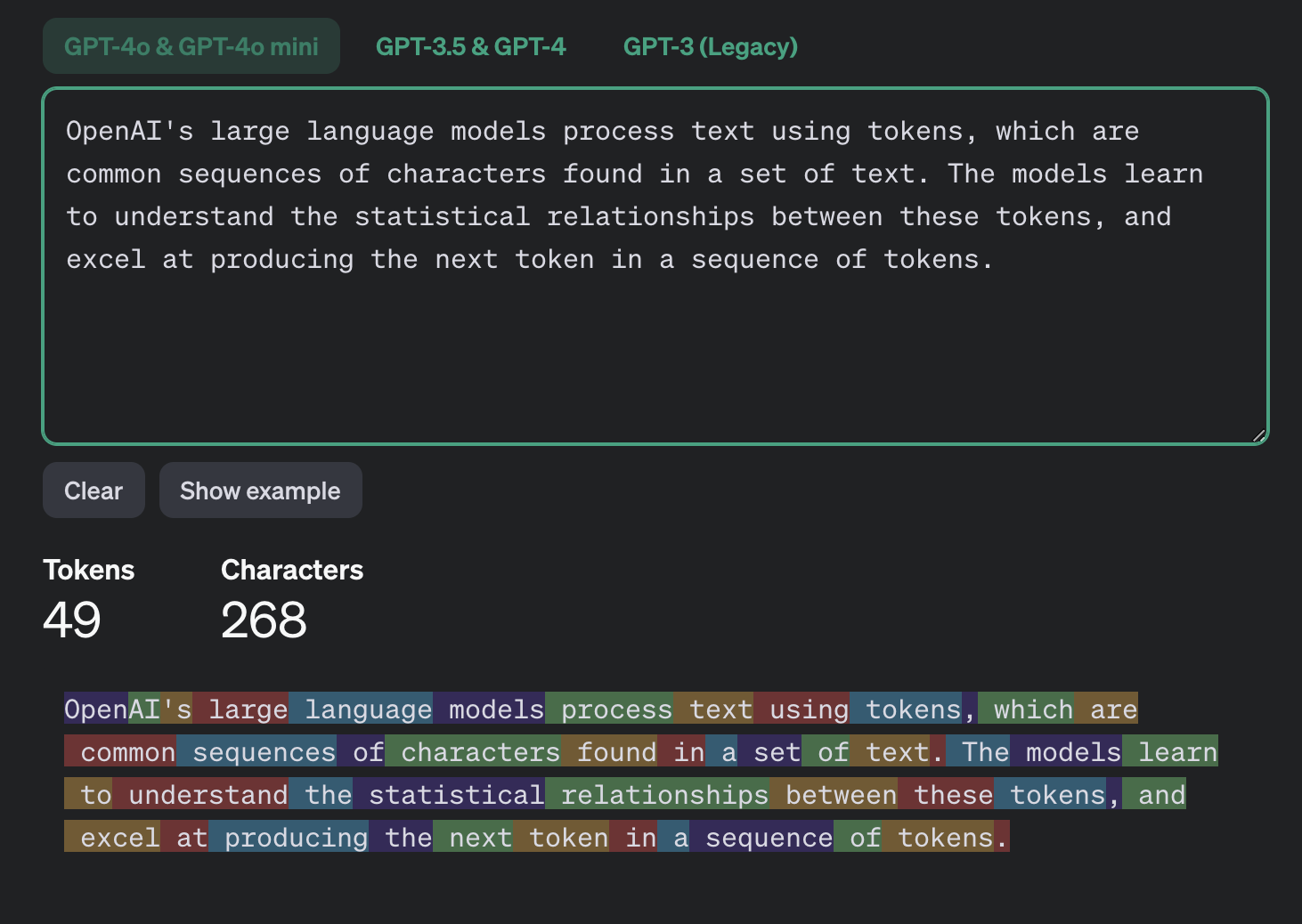
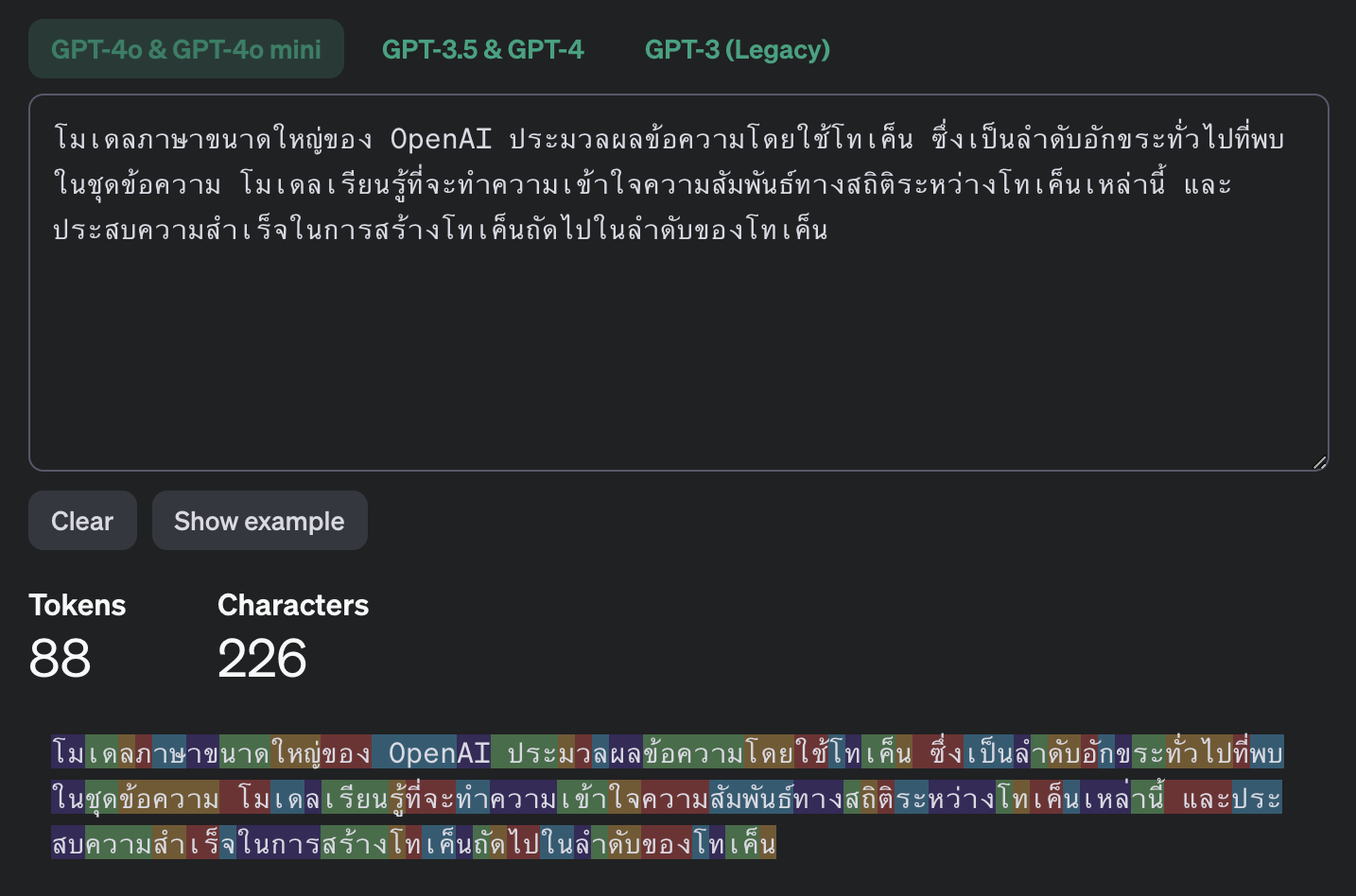
ถ้าใครสนใจอยากรู้เพิ่มเติมเรื่อง Tokenizer ลองดู Video ของ Andrej Karpathy ดูได้ค้าบ
มาถึงตรงนี้แล้ว น่าจะพอเห็นภาพคร่าว ๆ กันแล้วนะฮะว่า Token มันคืออะไร ทำงานยังไง เรามาดูเนื้อหาสำคัญใน Blog นี้กันดีกว่าครับ ว่าเราจะลดค่าใช้จ่ายกันยังไงได้บ้าง
1.ลองเลือกใช้โมเดลขนาดเล็ก
ยกตัวอย่างเช่น Claude 3 Haiku ราคา $1.25 ต่อ 1 ล้าน output tokens, ในขณะที่ Claude 3.5 Sonnet ราคาอยู่ที่ $15 ต่อ 1 ล้าน tokens
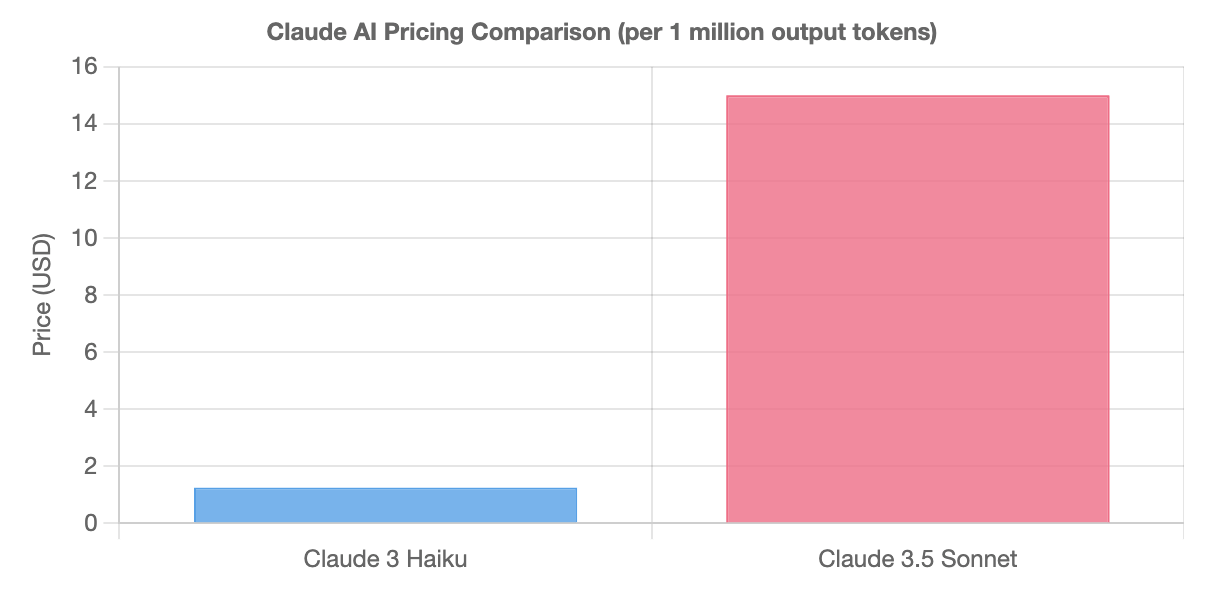
นั่นแปลว่า การเลือก โมเดลที่เหมาะสม (หรือปรับ Prompt เพื่อให้ใช้ โมเดลขนาดเล็กได้) สำคัญอย่างมากในการควบคุม Cost ที่เกิดขึ้น
การเลือก โมเดลขนาดใหญ่ จะมีข้อดีในเรื่องความ Generic ใช้ง่าย ใช้ได้หลากหลาย ไม่ต้อง prompt ละเอียดก็ทำงานได้, แต่บางครั้งอาจแลกมากับความช้า และราคาที่สูงกว่า
ในทางกลับกันการเลือก โมเดลขนาดเล็กกว่า ก็มักจะเร็วกว่า และถ้าเรา prompt มันดีดี อาจจะให้ผลลัพธ์ที่ ใกล้เคียง กับ โมเดลใหญ่ ในราคาที่ถูกกว่าก็ได้ฮะ
ใช้โมเดลเล็กกับ task-specific
แน่นอนฮะ ว่าการใช้ โมเดลที่ใหญ่กว่า เราจะได้ความสามารถที่กว้างกว่า (General Knowledge) ซึ่งสามารถทำงานได้หลากหลาย แต่ในบาง use-case ยกตัวอย่างเช่น การสรุปข้อความ การดึงข้อมูลออกมาจากข้อความ หรือการจำแนกเนื้อหา ง่าย ๆ เราอาจจะเลือกใช้โมเดลที่มีขนาดเล็กลงมา ถ้าเราจัดการดีดี ผลลัพธ์ที่ได้อาจจะใกล้เคียงกัน เร็วมากขึ้นกว่าเดิม และราคาก็ถูกกว่าอีกด้วย
2.Prompt Compressions
Prompt Compressions คือการลดจำนวน input tokens โดยเลือกเฉพาะคำที่จำเป็น ลบคำที่ซ้ำซ้อนออกไป เช่น
ตัวอย่างข้างล่างนี้มี 279 ตัวอักษร ~53 tokens
Can you assist in creating a 500-word blog post on [specific topic]? I need help captivating readers with a captivating introduction, exploring three key points, and crafting a strong conclusion. It's vital to maintain a professional tone and incorporate subheadings for clarity.
เราสามารถเขียนให้สั้นลงได้เหลือ 172 ตัวอักษร ~ 38 tokens
Write a 500-word blog post on [specific topic] with an engaging introduction, 3 main points, and a strong conclusion, using a conversational tone and including subheadings.
นอกจากนี้ถ้าเราต้องการ Compress prompt แต่ไม่รู้จะเริ่มยังไง ลองเล่น LLMLingua ของ Microsoft ดูได้คร้าบ เค้า claim ว่าสามารถลดได้ถึง 20 เท่าโดยที่ยังได้ความแม่นยำเท่าเดิม

3.สรุปบทสนทนา
ถ้าเพื่อน ๆ กำลังพัฒนา Chatbot และต้องการเก็บ Memory หรือ Chat History การส่ง Chat History ทั้งหมดไปทุกครั้งอาจมีค่าใช้จ่ายสูง หนึ่งในวิธีที่เราสามารถทำได้คือให้ LLM สรุปบทสนทนาเป็นระยะ ๆ เพื่อลดจำนวน Input Tokens ที่ต้องใช้
4.ใช้ RAG (Retrieval Augmented Generation)
ถ้าเพื่อน ๆ ต้องทำงานกับ document หลายร้อยหน้า แทนที่เราจะโยนทั้ง document เข้าไปใน prompt เราสามารถทำ RAG เพื่อตัดบางส่วนบางตอนส่งเข้าไปก็ได้ครับ ท่านี้ แน่นอนว่าจะช่วยลด cost เนื่องจากเราไม่ต้องส่ง document เข้าไปทั้งหมด แต่จะไปสร้าง issue เรื่อง context ที่อาจจะไม่ครบ แต่ตรงนี้ก็มีวิธีแก้อยู่หลายวิธีครับ ยกตัวอย่างเช่น การทำ Contextual Retrieval ของ Anthropic ก็น่าสนใจครับ
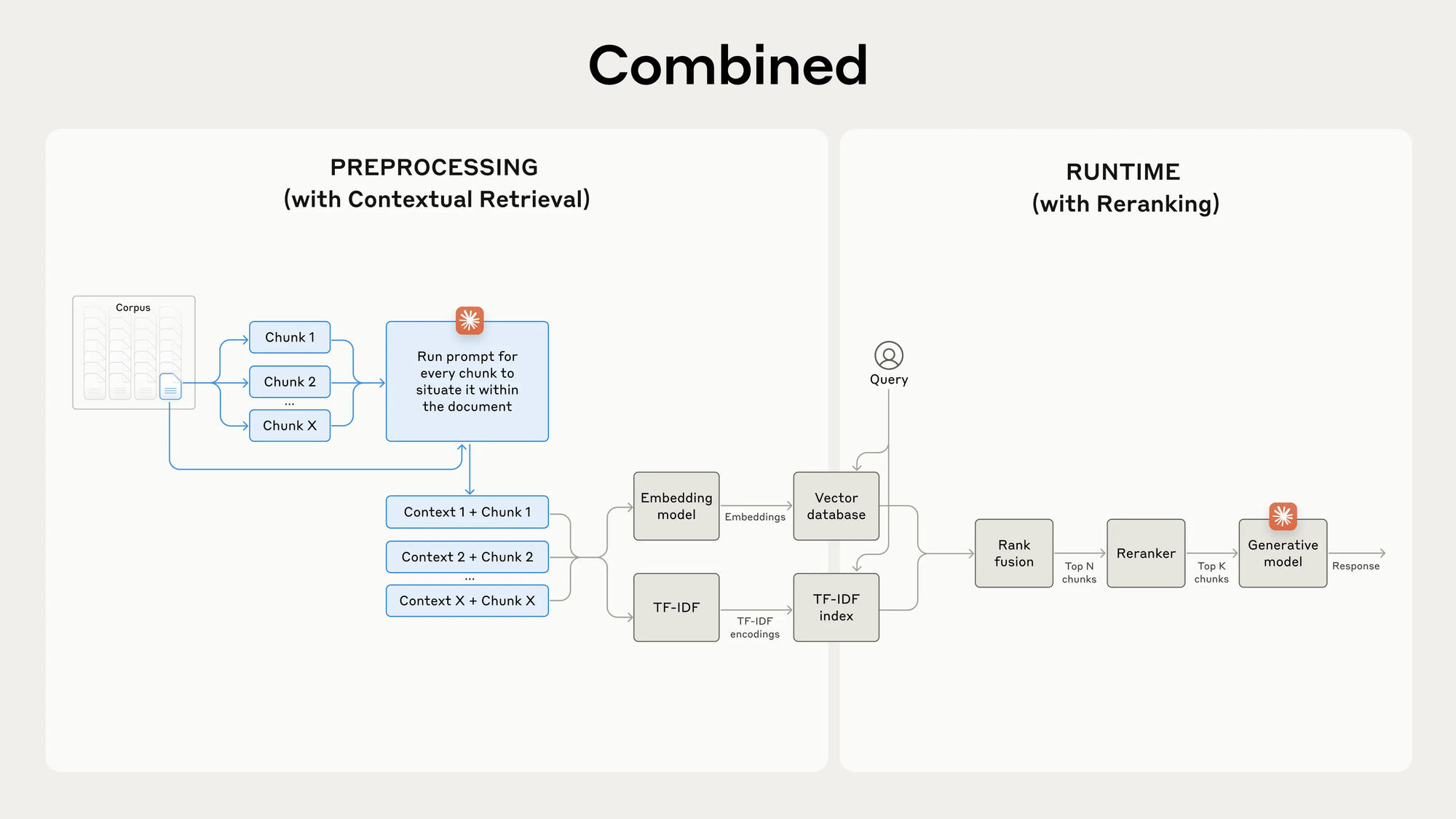

เพิ่มเติม Paper นี้ก็น่าสนใจครับ สรุปคือว่า
- โยนเนื้อหาทั้งหมดเข้าไปเลยได้ผลลัพธ์ที่ดีกว่า
- แต่ถ้าต้องการลด Cost การทำ RAG ยังคงเป็นตัวเลือกที่ดีครับ
- ใน Paper เค้าเสนอ SELF-ROUTE ซึ่งให้ model ทำการเลือกว่าควรจะโยนไปให้ Model ทีเดียวเลย หรือ ควรจะไป RAG
5.ใช้ YAML แทน JSON
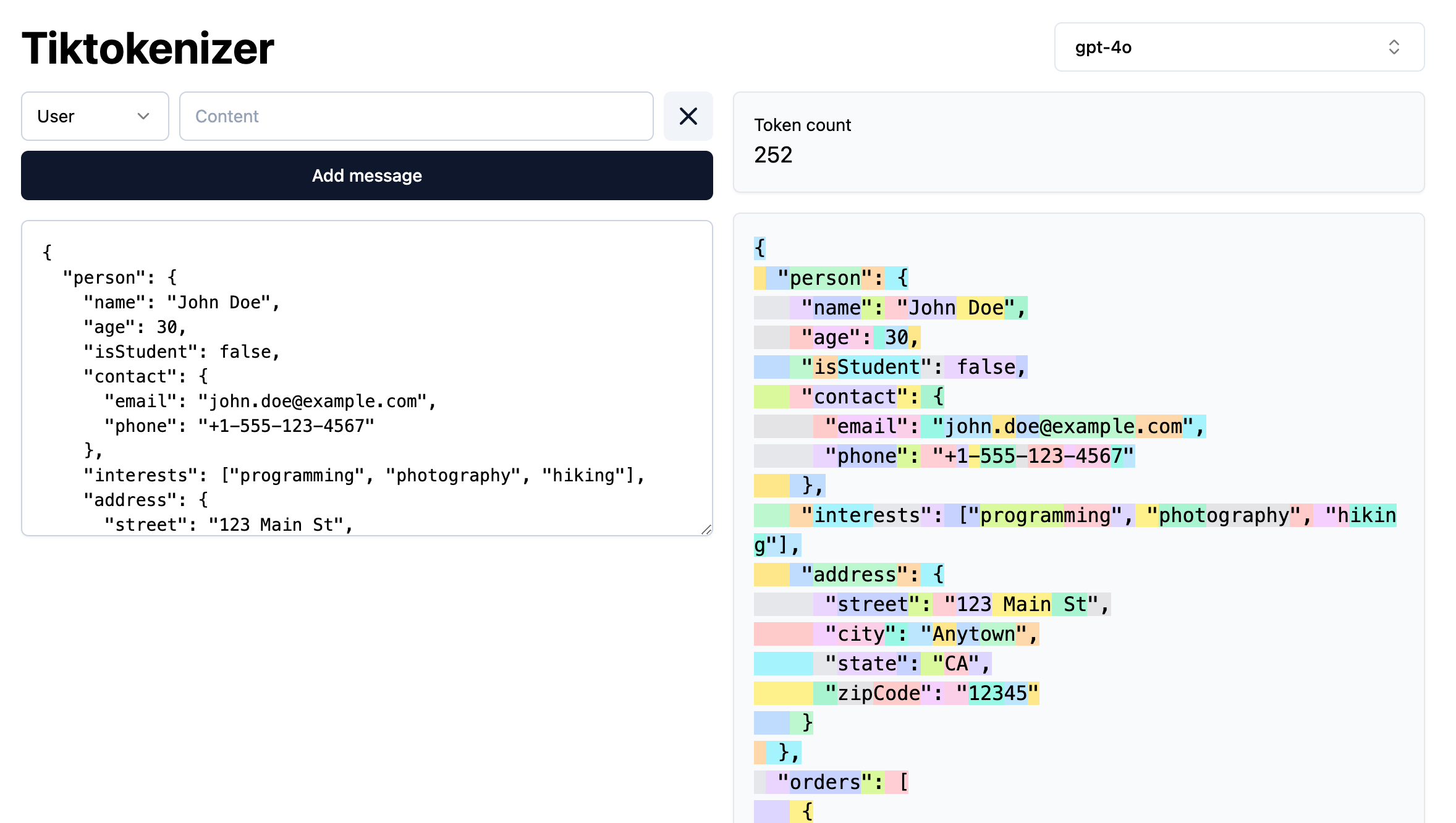
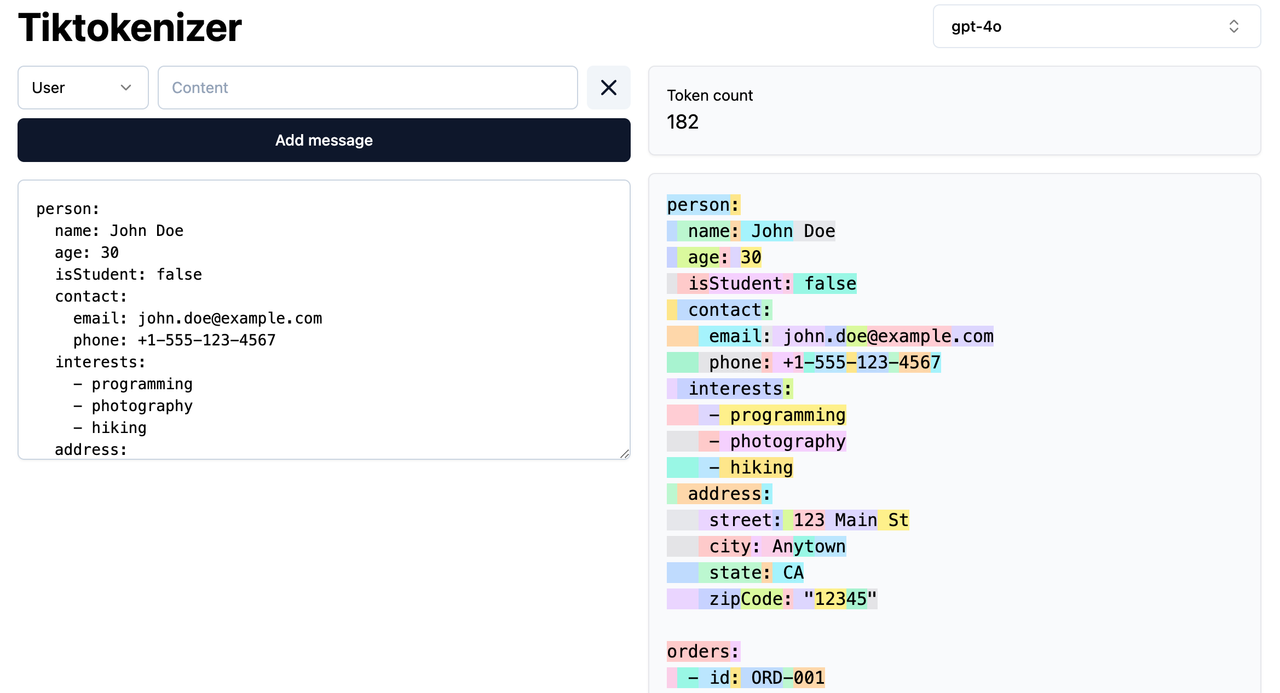
ถ้าเพื่อน ๆ ทำงานกับ Structured output อย่างเช่น JSON การเปลี่ยน format เป็น YAML ก็ช่วยลดจำนวน token ที่ใช้ได้มากเลยทีเดียวฮะ เนื่องจากเจ้า JSON ต้องมี วงเล็บ, คอมม่า มากมายเต็มไปหมด แต่ YAML มีน้อยกว่ามาก
ยกตัวอย่างนะฮะข้อมูลเดียวกัน JSON 252 Tokens แต่ใน YAML ใช้แค่ 182 tokens เท่านั้น – นี่เท่ากับเราประหยัด token ไปได้ถึง 30% เลยทีเดียว
Linkedin Engineering มีการ Mention ว่าเค้าก็ใช้ YAML แทน JSON เช่นกัน ยังไงใครสนใจก็ลองทดสอบกันดูได้ฮะ
6.ใช้ Batch API
ในบาง task ที่เราไม่ต้องการคำตอบแบบทันทีเลย ผู้ให้บริการบางเจ้า ก็จะมี Batch API ให้เราเรียกใช้งาน ซึ่งเราจะต้องทำการ Submit ไป แล้วจะได้ผลลัพธ์อีกที ภายใน X ชั่วโมง ยกตัวอย่างเช่น OpenAI ก็มี Batch API ให้เราใช้ ในราคาที่ถูกกว่า 50%
7. ใช้ LLM Router
ถ้าหากงานของเพื่อน ๆ มีรูปแบบ Query หลากหลายประเภท ลองทำความรู้จักกับ LLM Router กันดูครับ ตัว LLM Router คือเราจะทำการ Route Query ไปยัง LLM เช่น เรารู้อยู่แล้วว่า บางคำถามเป็นคำถามง่าย ๆ เราก็อาจจะเลือกใช้ โมเดลตัวเล็กที่ถูกกว่า หรือบางคำถามที่มันซับซ้อน เราก็เลือกใช้โมเดลตัวที่ใหญ่กว่าได้ครับ
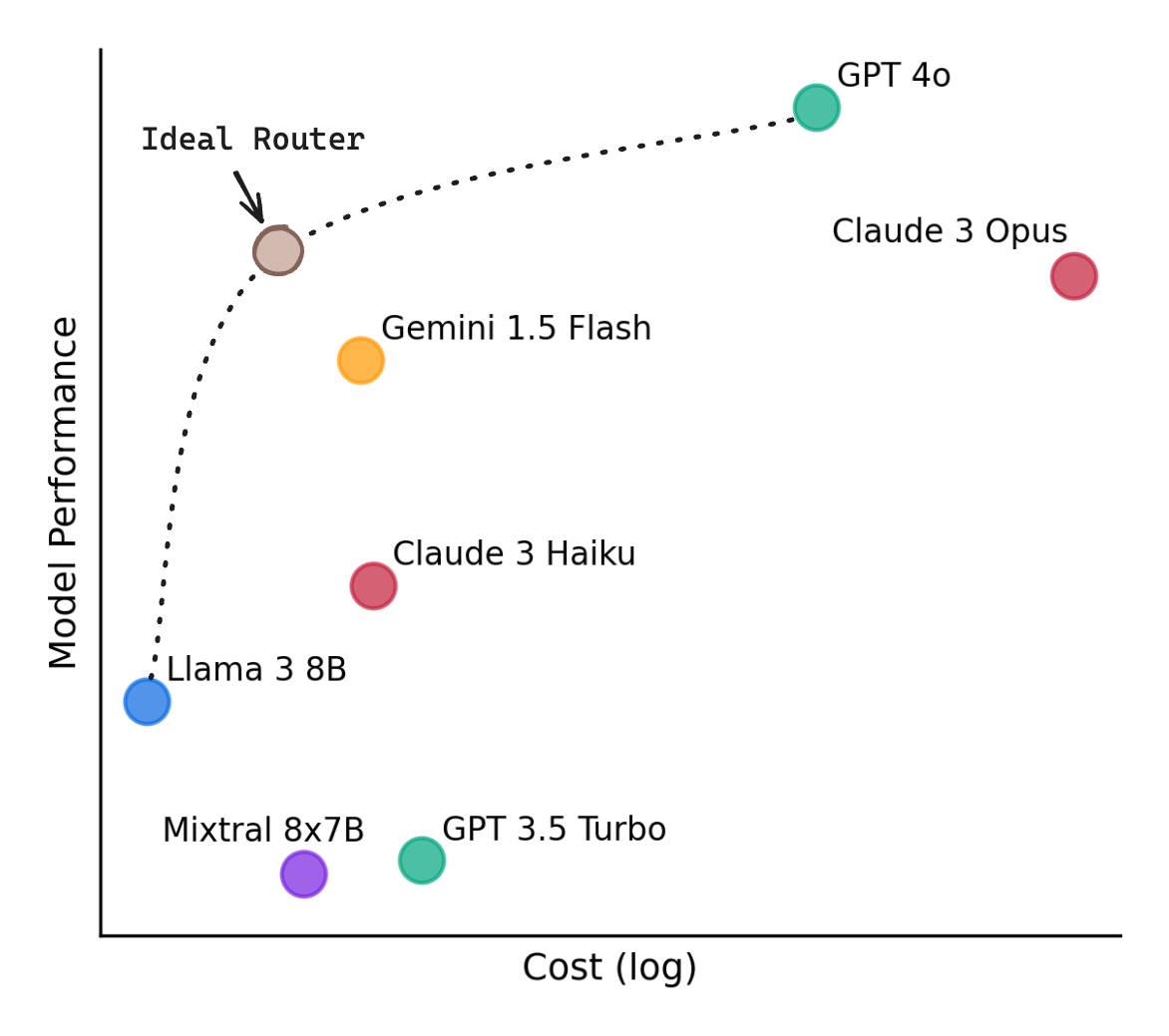
เพื่อให้ง่ายขึ้นสำหรับคนที่อยากลองใช้ดู ลองเริ่มจาก RouteLLM ดูได้ครับ เป็น open-source ที่เค้าเทรนมาแล้ว เราก็ใส่ชื่อโมเดลตัวใหญ่ตัวเล็กที่เราต้องการก็ใช้งานได้เลยยย
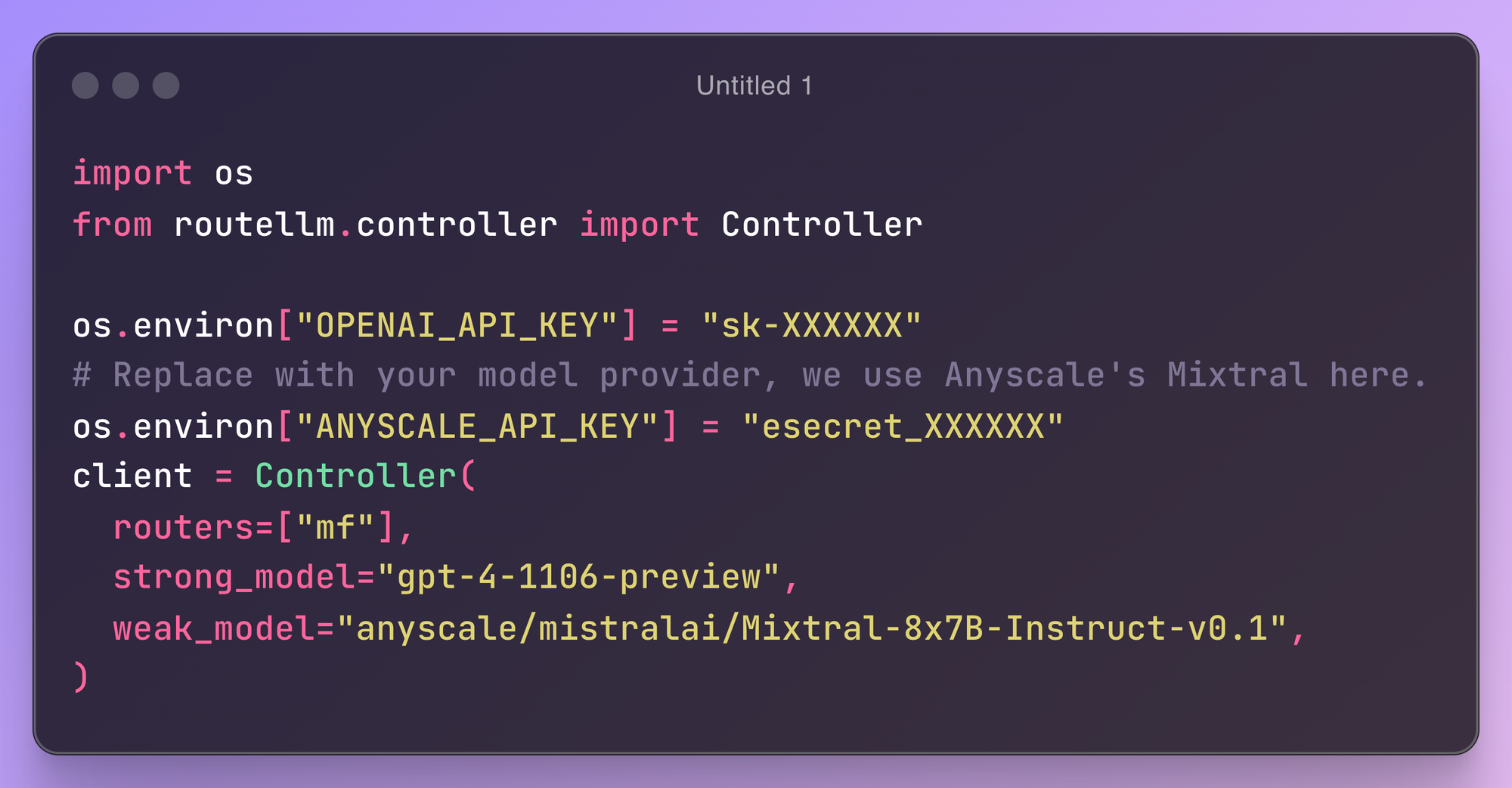
8.จำนวนครั้งที่เรียก LLM
นอกจากการ Optimize การเรียกแค่หนึ่งครั้งแล้ว ถ้า application ที่เพื่อนๆ กำลังทำอยู่จำเป็นตัวเรียกหลาย ๆ ครั้ง ลองดู List ข้างล่างเป็นไอเดียดูได้ครับ
8.1. Caching
การทำ Caching นอกจากจะช่วยลด Cost แล้วยังช่วยลด Latency อีกด้วย เพราะว่าเราสามารถตอบได้เลย โดยที่ไม่ต้องไปเรียก LLM อีก การ Caching ก็มีหลายแบบฮะ
- Traditional caching การทำ Caching แบบทั่วไป คือถ้า input เหมือนเดิมเป๊ะๆ ก็ตอบกลับไปเลย ใช้ในเคสที่เรามี pre-prompt UI เช่น ปุ่มกด เป็นต้น
- Semantic caching ไม่จำเป็นต้องมี input เหมือนเดิมก็ได้ แค่ใกล้เคียงกันมากเกิน threshold ที่เราตั้งไว้ ก็ตอบกลับไปได้เลย เครื่องมือที่น่าสนใจ เช่น GPTCache ที่ช่วยจัดการให้ หรือ ใครอยากจะทำเอง ควบคุมเองก็ เลือกใช้กันได้ตามสะดวกค้าบ
- Prompt Caching ผู้บริการบางเจ้า เช่น Anthropic, Gemini มี feature นี้ให้บริการครับ โดยเราไม่จำเป็นต้องส่งเนื้อหาเดิมซ้ำๆ ไปอีก เช่น document เดิม แต่เปลี่ยนคำถาม ใครสนใจก็ลองหาอ่านเพิ่มเติมดูได้นะคร้าบ

8.2. Batch Request
แทนที่เราจะเรียก LLM ทีละครั้ง เราอาจจะสามารถ รวบ Query เข้ามาครั้งเดียว แล้วเรียกทีเดียวก็ได้ครับ วิธีนี้จะช่วยลด input tokens ที่ต้องใช้ร่วมกันได้ เช่นพวก instruction, หรือ examples
แทนที่จะเรียกทีละ ตัวอย่าง
You are an AI language model trained to analyze and summarize text. Please provide a brief 2-3 sentence summary of the plot for the following book:
To Kill a Mockingbird" by Harper Lee
Please provide your summary below:ก็เรียกทีเดียวไปเลยฮะ
You are an AI language model trained to analyze and summarize text. For each of the following book titles, provide a brief 2-3 sentence summary of the plot. Respond in a numbered list format.
1. "To Kill a Mockingbird" by Harper Lee
2. "1984" by George Orwell
3. "Pride and Prejudice" by Jane Austen
4. "The Great Gatsby" by F. Scott Fitzgerald
5. "The Catcher in the Rye" by J.D. Salinger
Please provide your summaries below:8.3. เข้าใจการทำงานของ Frameworks/Library
Frameworks/Library พวก LangChain หรือ LlamaIndex นี่บางทีมี API ให้เราใช้งานง่ายๆ หลังบ้านอาจจะมีการเรียก LLM หลายครั้งก็ได้นะครับ แนะนำว่าให้ไล่อ่าน Code หรือ Document ให้ละเอียด แล้วบางทีอาจจะเจอว่า เขียนเอง เรียกเองครั้งเดียว ดีกว่า ถูกกว่า ก็ได้ฮะ
ตัวอย่างข้างล่างคือ หนึ่งใน Response Model ของ LlamaIndex ที่เรียกว่า Tree Summarize จะเห็นว่า มีการเรียก LLM หลายครั้งเลย
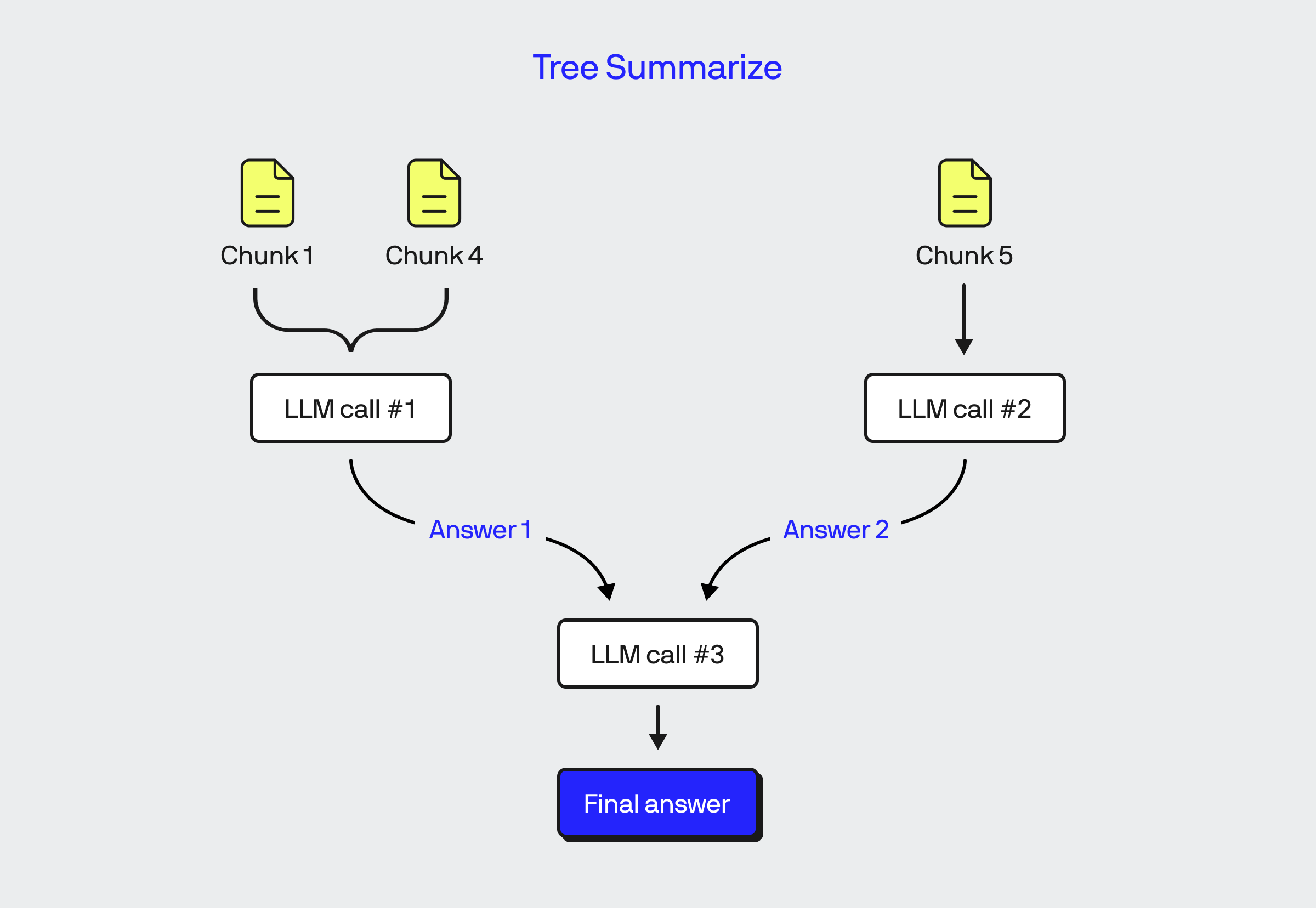
ใครใช้ LlamaIndex แล้วอยากเข้าใจเรื่อง Response Model เพิ่ม แนะนำตามไปอ่านของ BlueLabel ได้เลยคร้าบ
นอกจากนี้ ยังมี Technique อื่นๆ ที่น่าสนใจ อยู่อีกคร้าบ ใครสนใจเพิ่มเติมก็กดตามไปอ่านได้ฮะ
- LLM Cascade
- Finetune โมเดล
Monitor and evaluate
สุดท้ายนี้ แน่นอนครับสำคัญเสมอ คือ การ Monitor และ Evaluate ผลลัพธ์อยู่ตลอดเวลาฮะ อาจจะใช้ monitoring tool เช่น LangSmith, LangFuse หรืออื่น ๆ ที่ตอนนี้มีมากมายเต็มไปหมด เครื่องมือเหล่านี้ จะช่วยให้เราทดสอบ และตรวจสอบ cost และการใช้งาน application ของเราได้ดีทีเดียวฮะ
บทสรุป
การจัดการค่าใช้จ่ายของ LLM เป็นหนึ่งในเรื่องสำคัญที่จะทำให้เราใช้งาน LLM ได้อย่างสบายใจ และมีประสิทธิภาพ การเข้าใจตัวแปรที่ส่งผลต่อค่าใช้จ่ายของ LLM application เช่น ขนาดโมเดล, จำนวน Token ที่ใช้งาน, ผู้ให้บริการแต่ละเจ้า ทำให้เราสามารถวางแผนและเลือกใช้ LLM ได้อย่างมีประสิทธิภาพฮะ
สรุปแล้ว การใช้ LLM ให้คุ้มค่านั้น ต้องคำนึงถึงสมดุลระหว่างประสิทธิภาพ ต้นทุน และประสบการณ์ของผู้ใช้ครับ ถ้าทำได้ดี รับรองว่าเพื่อน ๆ จะได้ใช้ LLM อย่างสุดคุ้ม ไม่ต้องกลัวว่ากระเป๋าจะฉีกแน่นอน! 💪
แล้วเพื่อน ๆ ล่ะครับ มีเทคนิคเด็ด ๆ ในการประหยัดโทเค็นยังไงบ้าง? แชร์กันมาได้นะฮะ ไว้คราวหน้าเราจะมาคุยเรื่องอะไรสนุก ๆ เกี่ยวกับ LLM กันอีก อย่าลืมติดตามกันด้วยนะคร้าบ บ๊ายบาย! 👋😊