LLMOps คืออะไร


Large Language Models (LLMs) ยังคงร้อนแรงอยู่นะฮะ 🔥 ตอนที่เขียนอยู่นี้ น่าจะมีหลายบริษัทเริ่มนำไปลอง นำไปใช้สร้างเป็น use-cases ออกมากันบ้างแล้ว แต่การจะเอา LLM ไปใช้จริงๆ นั้นก็ยังมี challenges อีกเยอะเลย ตั้งแต่ขั้นตอนสร้าง จนถึงการ deploy และดูแล

ในบทความนี้จะพามาทำความรู้จักกับ LLMOps (บางส่วน) กันฮะ LLMOps คือชุดของ best practices และ tools ต่างๆ ที่จะช่วยให้ทีม AI Engineer และ Developer สามารถพัฒนา ทดสอบ deploy และ monitor LLM application ได้ง่ายและมีประสิทธิภาพมากขึ้นนั่นเอง
LLM Lifecycle
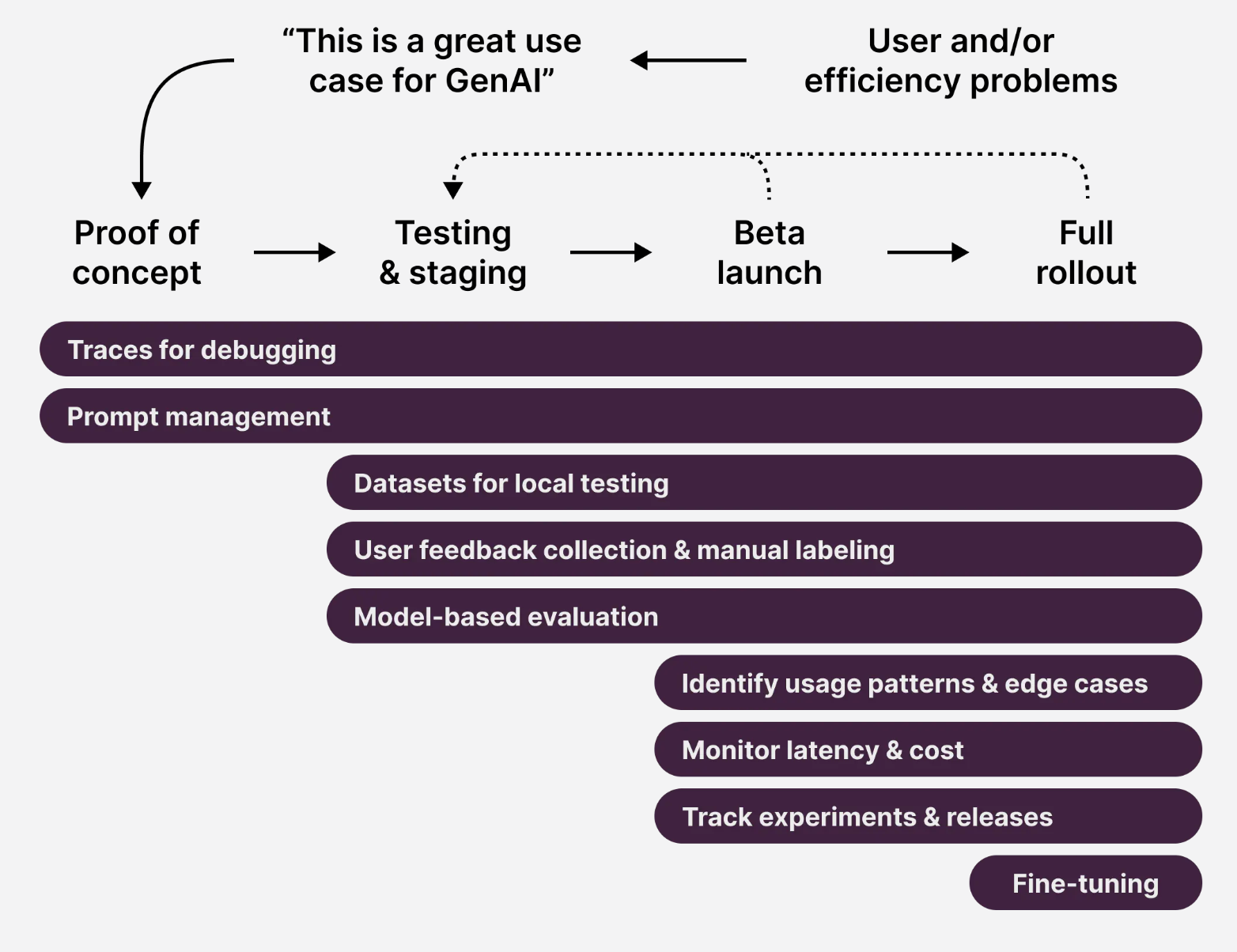
เริ่มจากเรามาดู Lifecycle ของการพัฒนา LLM กันก่อนฮะ Microsoft เค้าแบ่ง LLM Lifecycle ออกเป็น 3 phase ใหญ่ ๆ 1) Ideating/exploring, 2) Building/augmenting, และ 3) Operationalizing

Ideating/exploring
ขั้นแรกนี้เป็นการคิดหาไอเดียกันก่อนฮะ ว่าปัญหาที่มี LLM สามารถช่วยแก้ปัญหาได้ไหม อาจจะเป็นการ prototype ขึ้นมา เขียน prompt และเลือก model ที่เหมาะสม วนไป จนกว่าจะเริ่มเห็นเป็นรูปเป็นร่าง
Building/augmenting
เฟสถัดมา เราเริ่มเอา data จริงมาใช้ 😎 เริ่มมีการปรับด้วยวิธี prompt engineering, fine-tuning, RAG และอื่นๆ จุดนี้เราจะเริ่มเห็นปัญหา เห็นข้อจำกัด ที่เราต้องจัดการละฮะ เช่น ตอบผิดตอบมั่วแก้ยังไงดี ตอบแล้วไม่พอใจ ทำยังไง ขั้นตอนนี้ Evaluation เป็นเรื่องสำคัญฮะ
Operationalizing
เมื่อพร้อมแล้วก็ deploy ระบบเพื่อใช้งานจริง พร้อมทั้ง monitor ประสิทธิภาพ และแก้ปัญหาต่างๆ ที่อาจจะเกิดขึ้น เฟสนี้เราจะต้องคอย monitor ฮะ ไม่ว่าจะเป็น Cost เยอะกว่าที่คาดไหม, Latency ของ request ไหน เยอะกว่าปกติรึเปล่า มี use-case อะไรที่เราไม่ได้คาดคิดไว้ไหม เราก็จะนำข้อมูลที่เรา monitor ไว้ มา improve application ของเราต่อไปฮะ
Why we need LLMOps
- The need for customisation: แต่ละ task ก็ต้องใช้เทคนิคที่ต่างกันเพื่อให้ได้ performance สูงสุด เลยต้องมีการปรับแต่งด้วยวิธีต่างๆ เช่น Prompt Engineering, RAG และ fine-tuning นั่นเอง
- API changes: LLM ส่วนใหญ่จะเข้าถึงผ่าน API ของคนอื่น ซึ่งมีการเปลี่ยนแปลงหรือเลิกใช้ได้ตลอด ต้องคอย monitor อยู่ตลอดฮะ เช่น OpenAI API มี spec เปลี่ยนไหม ตอบช้าลงไหม ตอบเหมือนเดิมรึเปล่า
- Data drift: เวลาใช้งานจริง data ที่เจอจะค่อยๆ เปลี่ยนไปอันนี้ Concept เหมือน MLOps เลยครับ เราก็ควรจะ Monitor ฮะว่า user ยังใช้เหมือนเดิมไหม เราควรจะอัพเดท Model หรือ ปรับแต่ง Prompt ตอนไหน
- Model evaluation: ML ทั่วไปเราอาจจะวัดผลจาก accuracy, precision, recall แต่พอเป็น LLM ที่ output เป็นภาษามนุษย์ จะวัดยากขึ้น้ครับ โดยเฉพาะเวลาไม่มี ground truth ให้เทียบเนี่ย 😫
- Monitoring: การ monitor เป็นเรื่องสำคัญมากสำหรับ LLM application เพื่อให้มั่นใจว่ามันทำงานได้ดีและเสถียร ซึ่งก็ซับซ้อนกว่าแอพทั่วไปเล็กน้อยฮะเพราะต้อง monitor หลายมิติ
How LLMOps addresses these challenges
Prompts and Prompt Management
การจัดการ Prompt ด้วย version control นี่ค่อนข้างสำคัญเลยฮะ เพราะการเปลี่ยนคำไม่กี่คำ อาจส่งผลต่อ LLM application ของเราได้
- การพัฒนา prompt ให้มีประสิทธิภาพเป็นสิ่งสำคัญมากในการลดความเสี่ยงและรักษาความปลอดภัย LLMOps เลยมีระบบจัดการ prompt อย่างเช่น Prompt CMS (Content Management System) ไว้คอยช่วย
- Prompt CMS ทำให้แยกส่วนต่างๆ ได้ คนที่ไม่ใช่ technical ก็สามารถสร้างและอัปเดต prompt ได้โดยไม่ต้อง re-deploy ทั้งแอป นอกจากนี้ tool บางตัวยังมีระบบ versioning กับ rollback อีกด้วย

Pipeline Management
บางทีการจัดการ pipeline มันก็ซับซ้อนเหลือเกิน 😅 เราอาจต้องการตัวช่วยให้เราออกแบบและจัดการ pipeline ที่ซับซ้อนพวกนี้ได้ง่ายขึ้น
เช่นตัวอย่างนี้เป็น Promptflow ของ Microsoft ที่ให้เราวาด pipeline เป็น flow diagram ได้เลย สะดวกสุดๆ ไปเลย

Fine-tuning and Experimentation
- LLMOps ทำให้เราเลือกข้อมูลจาก tracing log มาสร้าง dataset สำหรับ fine-tuning ได้ ช่วยให้ปรับปรุง LLM application ได้อย่างต่อเนื่อง
- เราสามารถเอาข้อมูลที่เราเลือกมาแล้ว export ออกไปทำ fine-tuning ได้ด้วยนะฮะ
API change management
แน่นอนฮะว่า API change management เป็นเรื่องที่เราต้อง Monitor บางเจ้าเราสามารถตั้ง Alert ไว้ได้ด้วยว่า มันแปลกไปจากปกติรึเปล่า จริงๆ ตรงนี้จะเหมือนกันกับ Alert system อื่น ๆ ฮะ เช่นพวก NewRelic
Evaluation and metrics
Evaluation นี่สำคัญมากอย่างที่บอกไปข้างต้นฮะ ถ้าอยากให้ LLM Application ทำงานได้ดี ก็ต้องเช็คอย่างสม่ำเสมอ 📊

Types of evaluators
- Heuristics: ประเภทนี้คือเราเขียนโค้ดขึ้นมาทดสอบครับ เช่น เช็คว่า output เป็น ค่าหรือคือ JSON format ตามที่เราต้องการรึเปล่า ในบางเคส เราอาจจะเขียนขึ้นมาวัดคะแนนความคล้ายระหว่าง output กับ reference เช่น เราให้ LLM ทำการ extract หัวข้อ ออกมาจากข่าว เราอาจจะเทียบว่า หัวข้อใกล้เคียงกับที่เราต้องการไหม ถ้าใกล้กันมากกว่า 95% ถือว่าผ่าน แบบนี้เป็นต้นฮะ
- LLM-as-judge: เป็นการใช้ LLM ในการให้คะแนน output เช่น เช็คว่า output มีเนื้อหาไม่เหมาะสมไหม หรือตรวจสอบว่า output มีความหมายเหมือนกับตัวอย่างหรือเปล่า เราก็สร้าง Prompt ขึ้นมาแล้วก็ถาม LLM เลยฮะ
- Human: ในบางเคส เราอาจจะต้องการประเมินด้วย Human เช่น ทำงานกับ Domain expert แล้วอยากให้เค้าช่วยประเมินว่าผลได้ที่ได้ถูกไหม หรือเวลาทำงานกับ ฟีเจอร์ใหม่ ๆ เราอาจจะต้อง evaluate ด้วยคนฮะ
PROMPT = """You are an expert professor specialized in grading students' answers to questions.
You are grading the following question:
{input}
Here is the real answer:
{reference}
You are grading the following predicted answer:
{prediction}
Respond with CORRECT or INCORRECT:"""ตัวอย่าง Prompt สำหรับ LLM-as-judge
LLM-as-judge ดีจริงหรือ?
ล่าสุด (May 10, 2024) Chip Huyen มาแชร์ใน X ฮะ ว่า
- AI-as-a-judge ให้คะแนนแบบคาดเดาไม่ได้ และจะเกิดจาก Model ที่เราใช้วัดผล อาจจะมี Bias ของข้อมูลที่เอามาเทรน บางตัวดี บางตัวก็ไม่ดี (อันนี้ต้องเลือกดูกันดีดีฮะ)
- อีกหลายอย่างที่เราต้อง tune นอกจาก Model ที่เราใช้ในการ Judge เช่น Prompt ที่เราใช้วัดผลดีแล้วหรือยัง (พวก prompt ที่ใช้ใน tool - out of the box อาจจะไม่ได้ตอบโจทย์ก็ได้), ลองรันสองรอบ ได้คะแนนเดิมรึเปล่า หรือตอบไม่เหมือนกัน
- อีกอย่างที่น่าสนใจคือ แกทำ Poll แล้วมีคนมาตอบว่า เงินที่ใช้เรียก Model สำหรับ evaluate แพงกว่าตอนใช้งานซะอีก
ที่มา: https://twitter.com/chipro/status/1788972359900389475
บทความของ Eugene อันนี้ก็น่าสนใจครับ เดี๋ยวไว้ผมมาเขียนเล่าอีกที แต่ว่าใครจะอ่านก่อนก็จิ้มลิ้งด้านล่างได้เลย
Metrics
เมตริก อาจจะแตกต่างกันไปตามแต่ละ use-cases ฮะ แต่หลัก ๆ น่าจะประมาณนี้
- Quality: accuracy, similarity, completeness, factual
- Cost: token per request
- Latency: response time, RPS
- Harm: bias, toxicity
- Honest: groundness
เดี๋ยวเขียนบทความเพิ่มลงรายละเอียดเกี่ยวกับพวก Metrics ดีกว่าฮะจะได้ลงละเอียดกว่านี้ 🚶ติดตามไว้ก่อนได้นะฮะ แต่ถ้าเป็นเรื่อง RAG ก็ตามไปที่ลิ้งข้างล่างก่อนเลย 👇
 Phasathorn Suwansri
Phasathorn Suwansri
Synthetic dataset
นอกจากเรื่องการประเมินแล้ว อีกสิ่งที่ขาดไม่ได้เลยคือ dataset ฮะ ผมเห็นหลายๆ คนในคอมมูนิตี้ใช้ synthetic dataset อยู่พอควรฮะ คือให้ LLM ช่วย paraphrase หรือสร้าง input ใหม่ๆ ให้ หรืออีกท่านึงคือเราเอา dataset จากการใช้งานจริงมาเพื่อเอาไปใช้งานต่อ
วิธี synthetic dataset ผมว่าน่าสนใจอยู่ฮะ เวลาที่เรามี dataset ไม่พอ หรืออยากได้ความหลากหลายมากขึ้น ก็ลองให้ LLM คอยช่วยสร้างเนื้อหาเพิ่มเติมดู จะได้ dataset ที่ใหญ่และครอบคลุมขึ้นสำหรับใช้ train model หรือประเมินความแม่นยำ
แต่ก็ต้องระวังนิดนึงฮะเวลาให้ LLM สร้างเอง เพราะมันอาจจะสร้างข้อมูลที่ไม่ค่อยสมจริงหรือมี bias ได้ เพราะฉะนั้นเราต้องคอยตรวจก่อนจะเอาไปใช้งานจริงนะอะ 😉
ตัวอย่างข้างล่างนี้ เค้าก็ย้ายจากการทำ evals ด้วยมือ มาใช้ LangSmith ก็ดูเหมือนง่ายแล้วดีนะฮะ
I just migrated my financial RAG evals to LangSmith.
— virat (@virattt) May 7, 2024
Previously, I was doing evals by hand.
Now, LangSmith takes care of:
• managing datasets
• evaluating correctness
• measuring latency
• visualizing prediction vs. answer
These features come built-in.
My financial RAG… pic.twitter.com/GZ7jFSmSfZ
Monitoring
Cost and Latency Monitoring
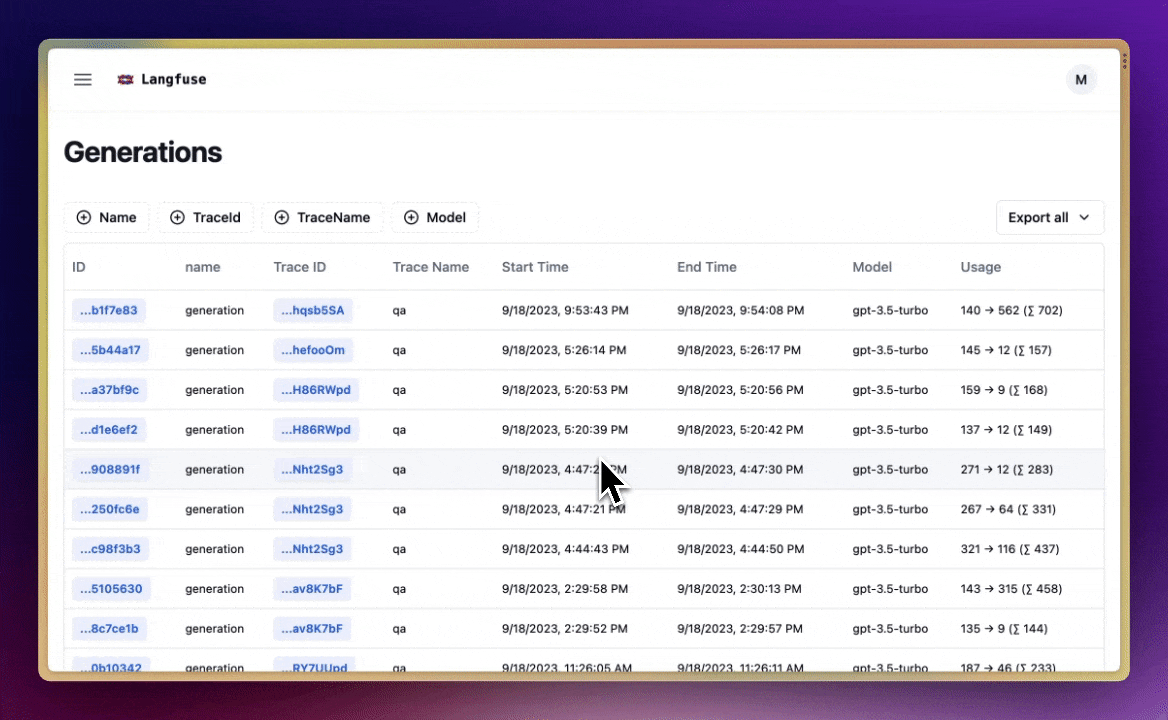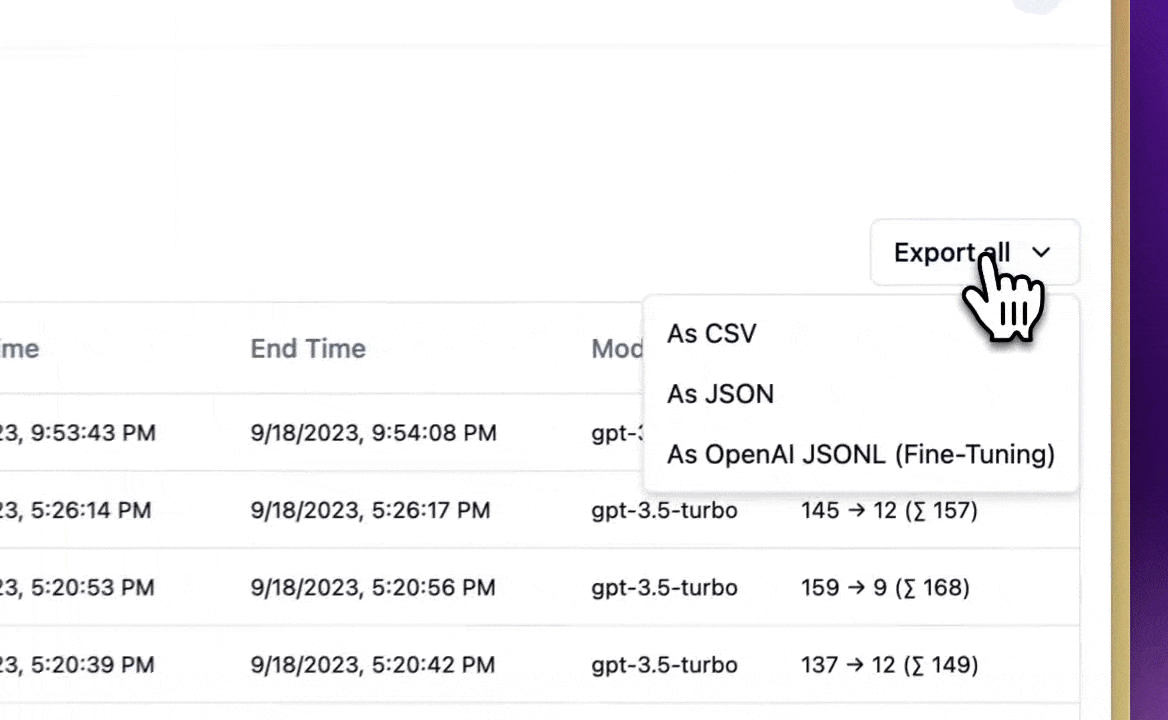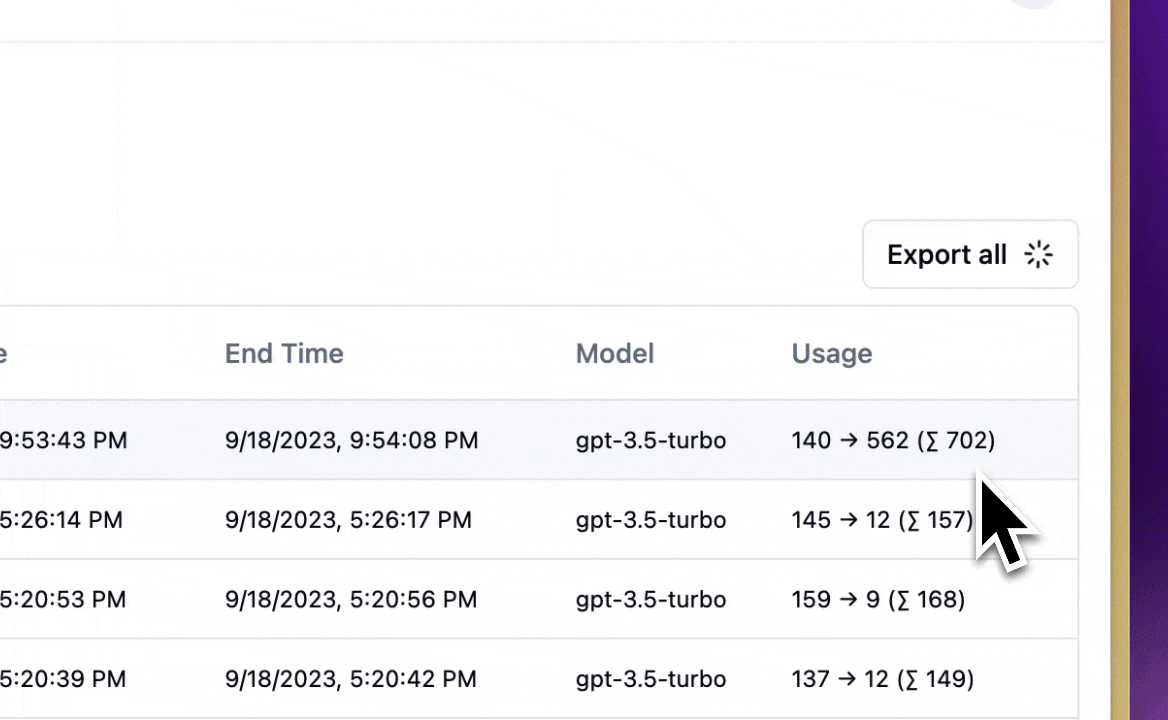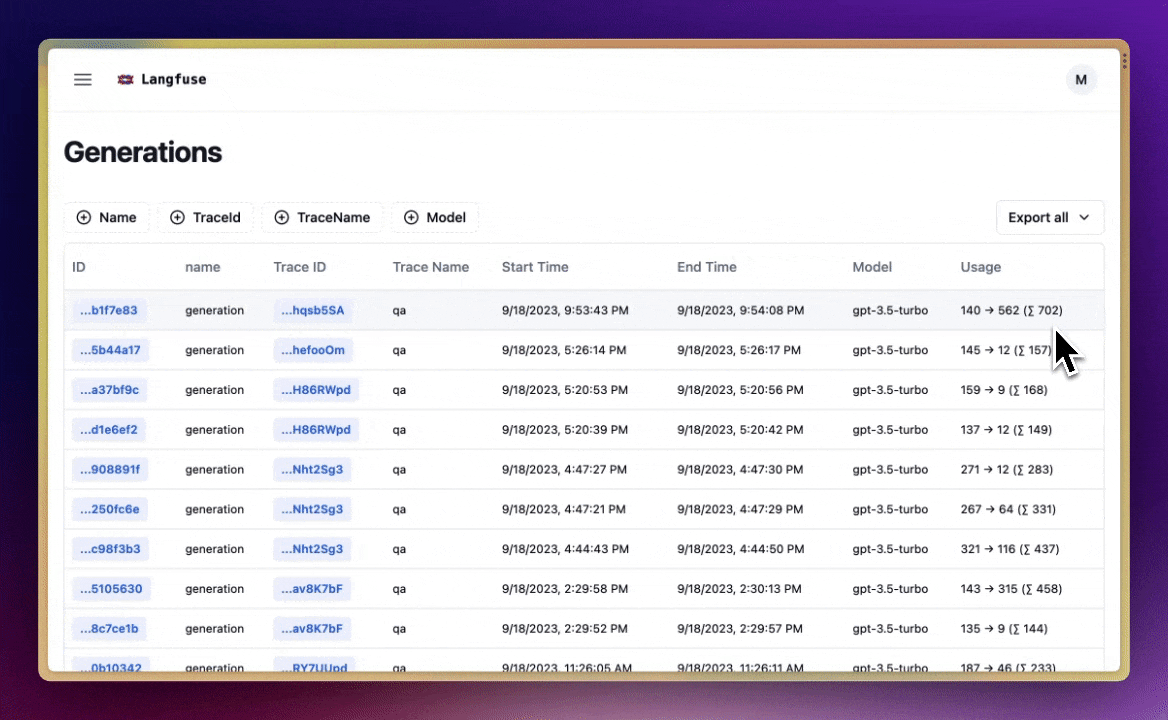
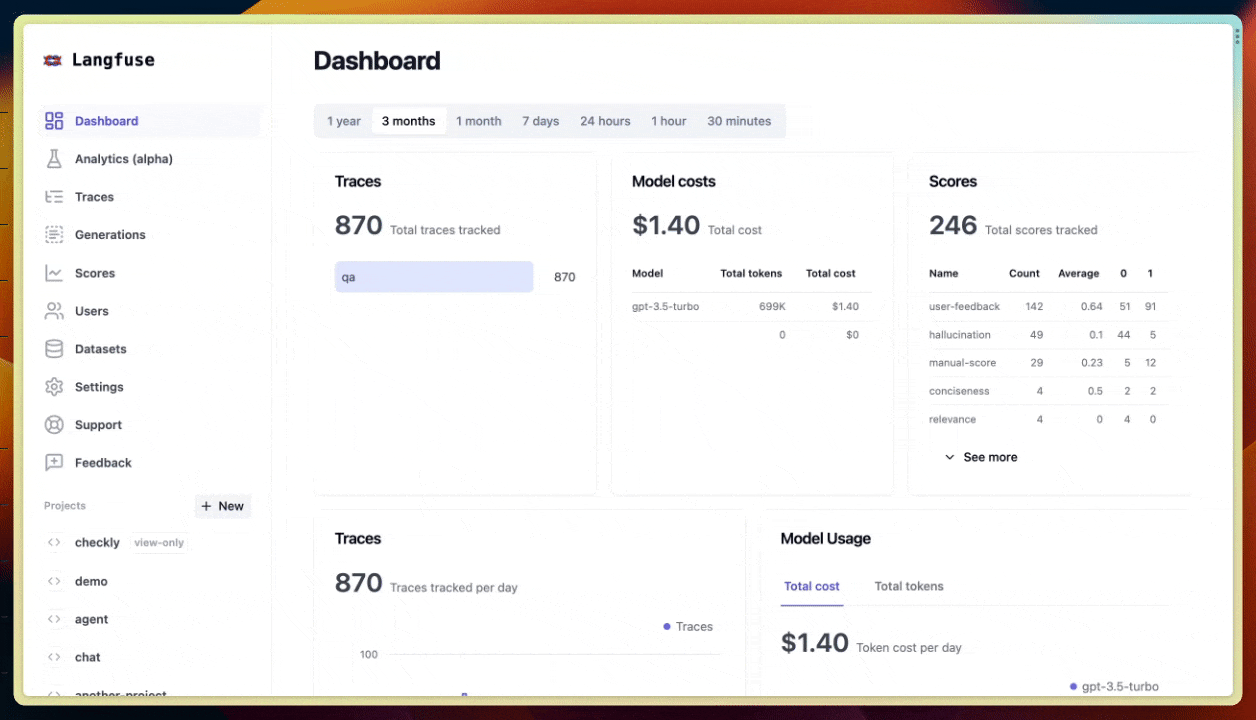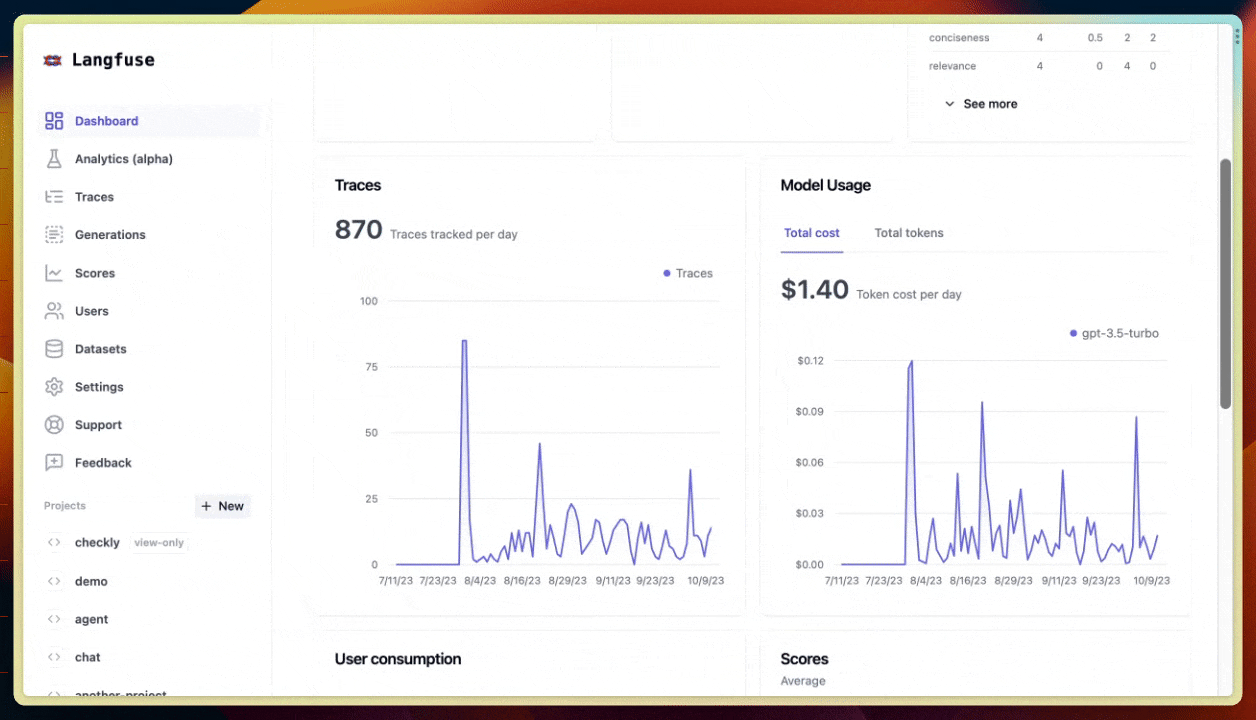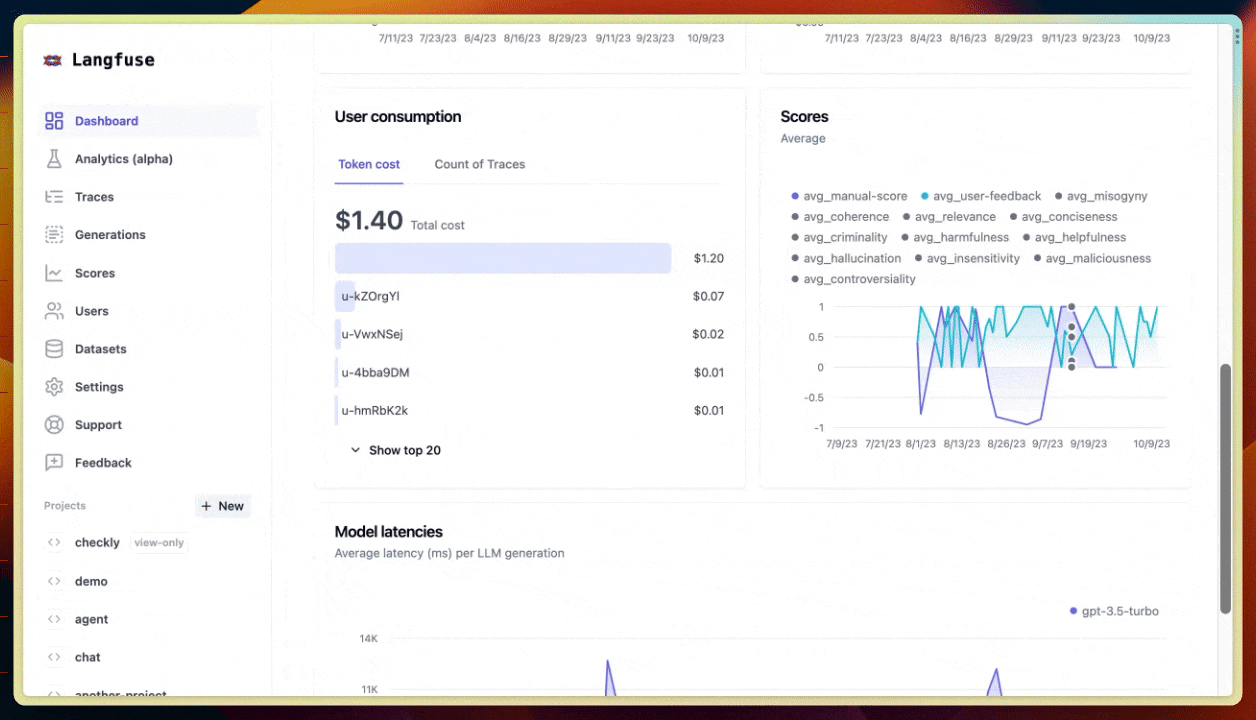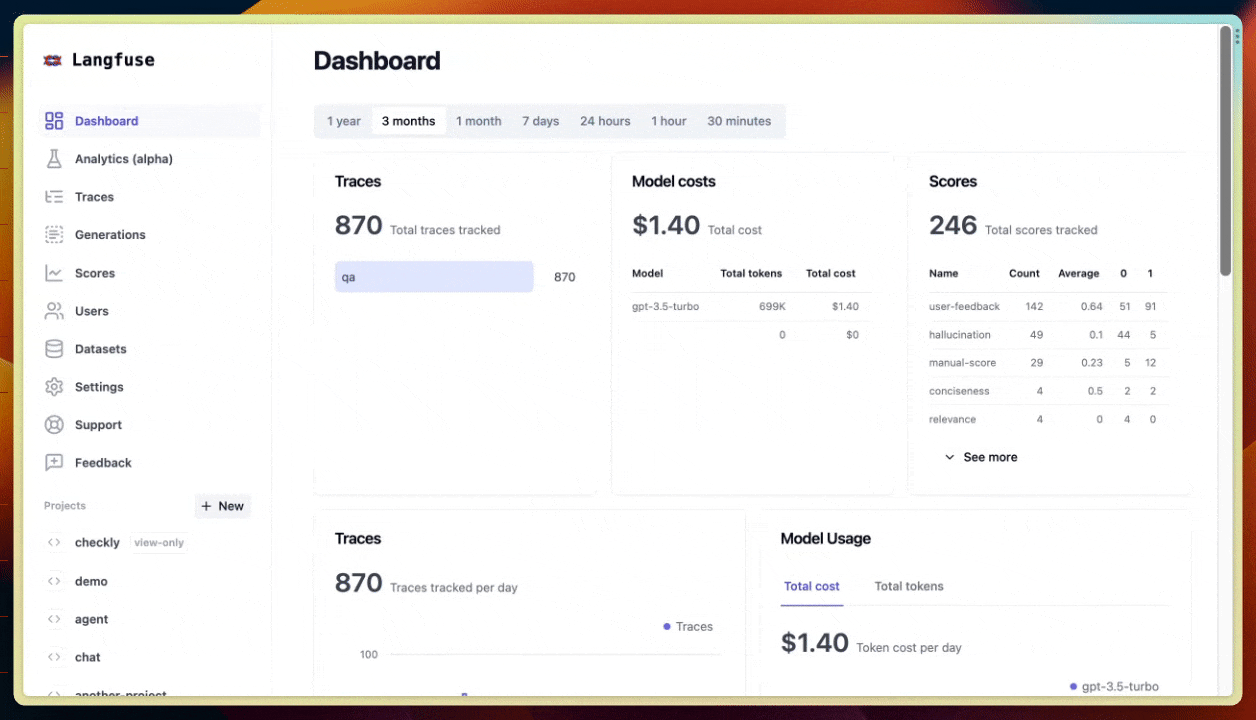
ข้อมูลเรื่อง cost, latency และ volume ต่างๆ นี่ช่วยเยอะฮะ ทั้งการ monitor การใช้งาน หา bottleneck หรือเพิ่ม performance ของระบบ 📈
เช่น เราสามารถตรวจสอบค่าใช้จ่ายจากโมเดล LLM ว่าเป็นเท่าไหร่ นับจำนวนครั้งที่เรียกใช้ LLM, token ที่ใช้ไป, ค่าเฉลี่ย latency, และจำนวน error ที่เกิดขึ้น เป็นต้น
เช่น ถ้าเห็นว่า cost พุ่งสูงมาก ก็รู้ว่าต้องหาทางลดการเรียก LLM ลงหน่อย หรือถ้า latency ช้าเกินไป ก็ต้องหาทางปรับปรุง performance กันแล้ว
อย่างในรูป เป็นหน้า Analytics ของ Langfuse ที่แสดงข้อมูลสถิติพวกนี้ให้เราดู เห็นแล้วก็วิเคราะห์ได้ง่ายๆ ว่าระบบเป็นยังไงบ้าง มีอะไรต้องแก้ไขปรับปรุงมั้ย
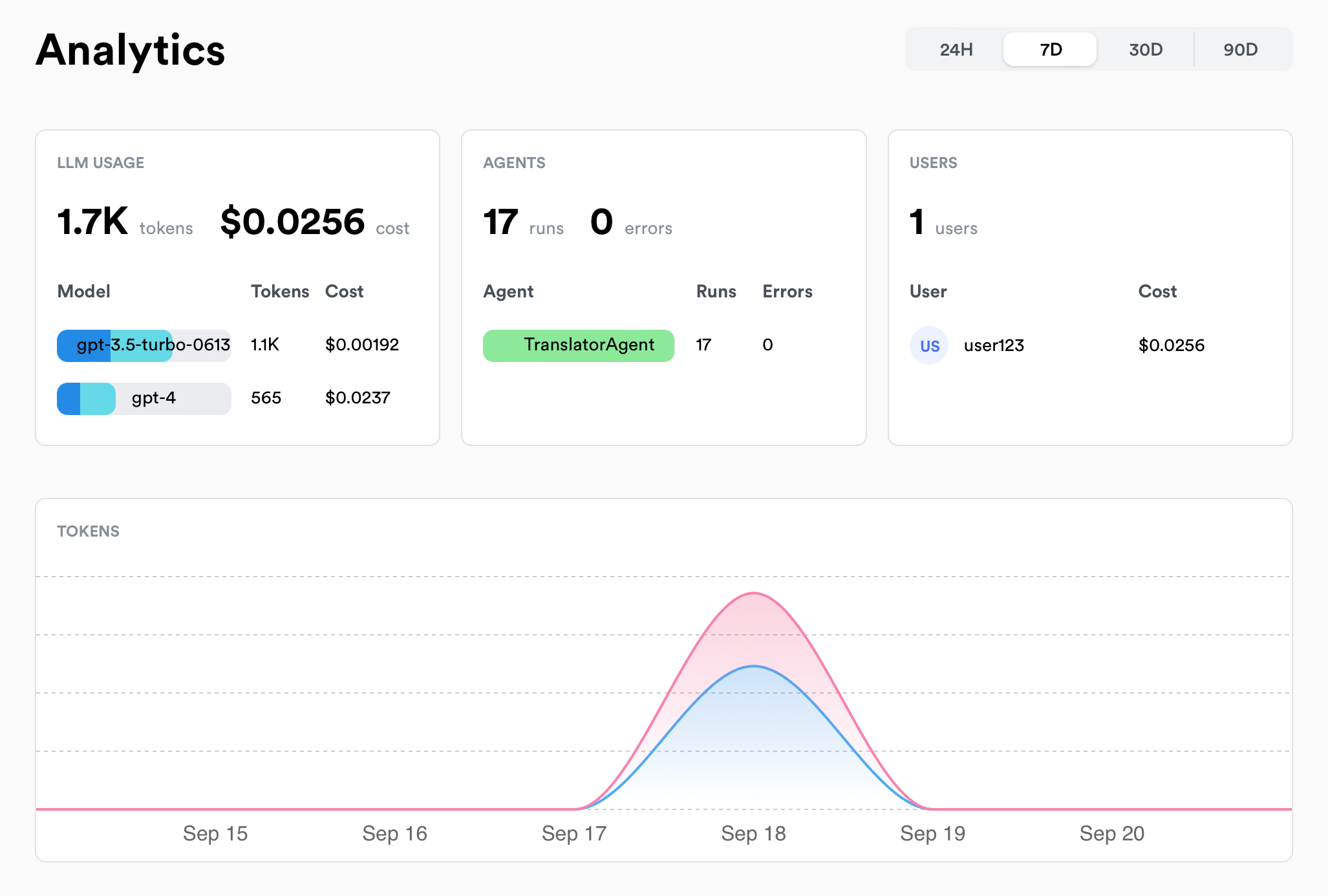
Usage Monitoring
เสริมจากด้านบนนิดหน่อยฮะ บางเคสเราอาจจะอยากหมุนข้อมูลดูว่า traffic คนใช้งาน หรือ cost ที่เพิ่มขึ้น มันเกิดจาก ผู้ใช้บางคน (super user) หรือ ผู้ใช้งานบางพื้นที่ (geolocation), เกิดกับบาง version รึเปล่า เราจะได้ investigate และจัดการกับปัญหาเหล่านั้นได้ดีขึ้นฮะ
อย่างภาพข้างล่างเป็นตัวอย่างลอง lunary ที่จะสามารถ group by user ได้ฮะ

Response monitoring
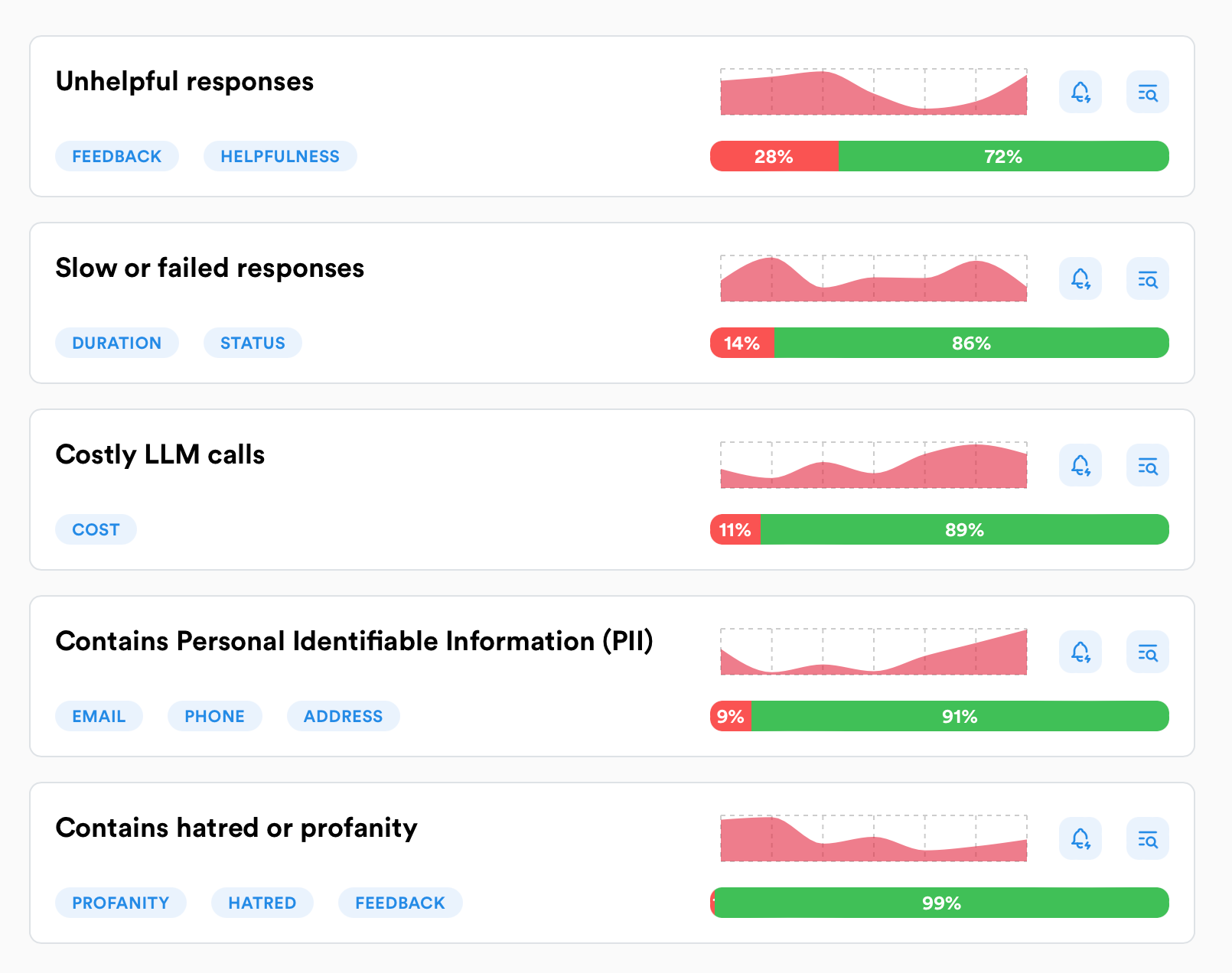
Continuous monitor ในหลายมิติ จะช่วยลดความเสี่ยงเวลาที่เรารัน LLM application ในระบบจริงได้เยอะฮะ 🚨
จากในรูป เราเห็นหน้า Radars ใน Lunary ที่ช่วยให้เรา monitor response ได้หลายมุม เช่น unhelpful response เยอะไหม, response ไหนตอบช้า หรือ fail รึเปล่า
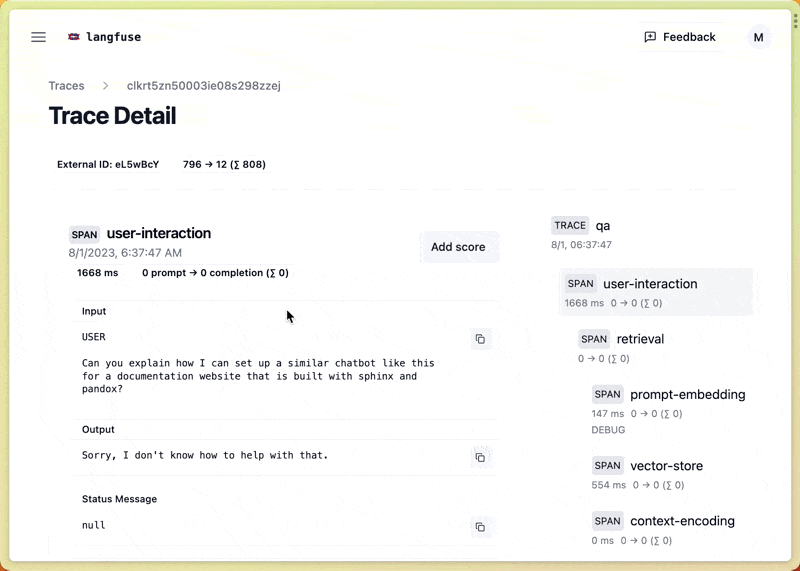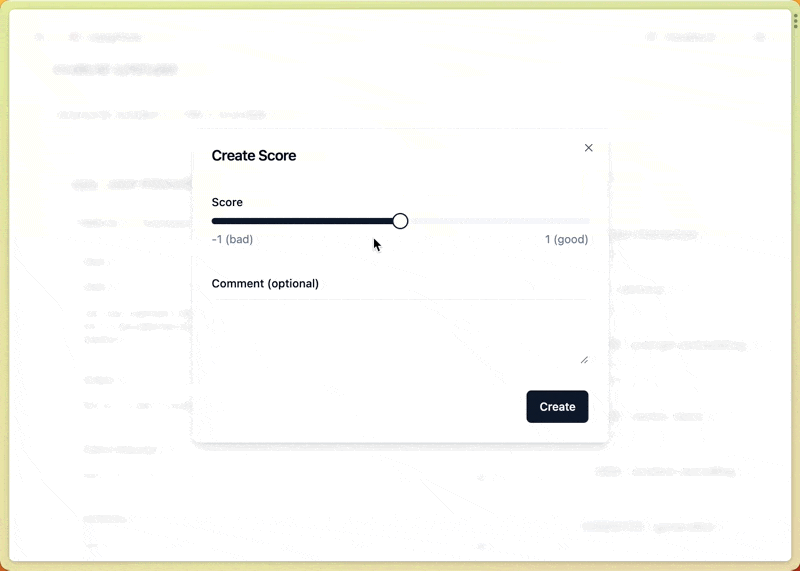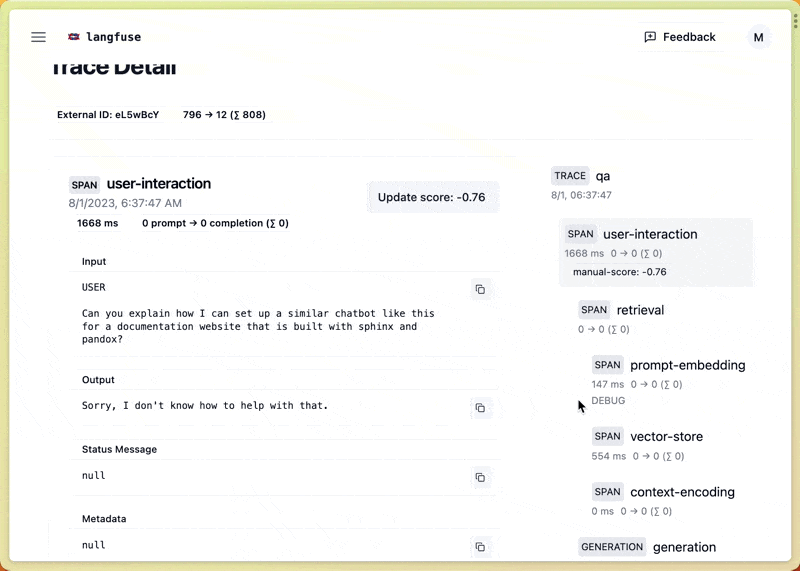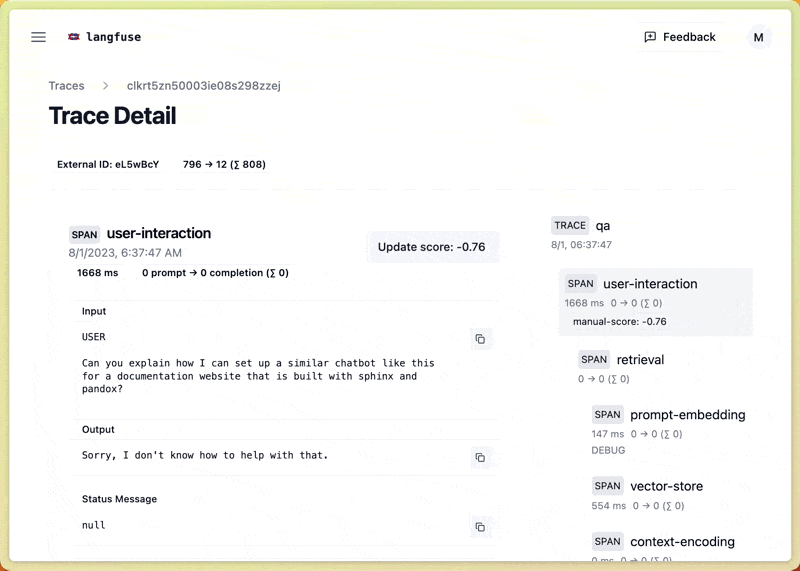
Traces and Debugging
อีกเรื่องสำคัญคือแปะ monitoring เข้าไปตั้งแต่ช่วง development เลยฮะ มันจะช่วยให้เราเห็นภาพรวมทั้งหมด แล้วก็ง่ายเวลา debug หรือ investigate issue ด้วย
ยกตัวอย่างเช่นใน chatbot ที่มีระบบถาม-ตอบ คำถามเดียวของผู้ใช้อาจจะต้องผ่านหลายขั้นตอน เช่น การเขียนคำถามใหม่ (query rewriting), การดึงข้อมูล (retrieving), การจัดอันดับใหม่ (reranking) และการสร้างคำตอบ (synthesizing)
ระบบ LLM monitoring จะช่วยให้เราระบุปัญหาและแก้ไขในแต่ละขั้นตอนได้อย่างง่ายดาย เหมือนกับตัวอย่างจาก Langsmith ในรูป ที่แสดงให้เห็น trace ของ request แต่ละอันอย่างละเอียด ไม่ว่าจะเป็น input, passages ที่ถูก retrieved มา, จนถึง output สุดท้าย เราสามารถดูได้ทุกขั้นตอนเลย
Conclusion
ในบทความนี้ ส่วนใหญ่จะพูดถึงการ develop และ monitor LLM Application แต่ยังมีอีกหลายส่วนที่ไม่ได้แตะในบทความนี้นะครับ เช่น fine-tuning, hardware, vector database หรือตัว LLM เอง ใครสนใจเพิ่มเติมก็ตามไปไล่อ่าน additional resource ด้านล่างได้นะฮะ หรือจะทักมาคุยกันก็ได้ฮะ 🕶️
การมี tools พวกนี้ไว้ในมือ ถือเป็นความได้เปรียบอย่างมากสำหรับทีม developer ที่ทำงานกับระบบ LLM เพราะมันช่วยให้เราแก้ปัญหาได้รวดเร็ว เข้าใจระบบลึกซึ้ง และพัฒนาต่อได้อย่างมั่นใจยิ่งขึ้น ใครกำลังพัฒนา LLM อยู่ลองนำเทคนิคพวกนี้ไปใช้กันดูนะฮะ รับรองว่าช่วยได้เยอะแน่นอน 💪
Tools
References

 Nik Spirin
Nik Spirin

Additional Resources

 tensorchord
tensorchord Prabal Deb
Prabal Deb Drew Robbins
Drew Robbins



 Samhita Alla
Samhita Alla

