GenAI Engineer Thailand #1 - PDF-to-text: A nightmare that never ends


ต่อจาก Session ที่แล้ว Self-hosted LLM on GCP, รอบนี้ น้องฟีน - AI/ML Engineer จาก ArcFusion.ai มาแชร์เรื่อง PDF-to-Text: A nightmare that never ends สำหรับใครที่พลาดไป ไม่ได้เข้ามาฟังใน Live ผมสรุปมาให้ใน blog นี้ครับ 🚀
ส่วนถ้าใครพลาด Self-hosted LLM on GCP ไป จิ้มข้างล่างเพื่อไปดูสรุปได้เลยคร้าบ 😄
 Phasathorn Suwansri
Phasathorn Suwansri
Table of contents
- Type of PDFs (Digital, Scanned)
- Problems when working with PDF (Image, Table, Text)
- Possible Solutions
- Conclusion
คุณฟีนเกริ่นว่า ในบางสถานการณ์เราต้องแปลงข้อมูล เช่นในรูปแบบของ PDF มาเป็น ภาพ, ตาราง, หรือข้อความ เพื่อเอาข้อความเหล่านั้นไปใช้งานต่อ
แต่ก่อนจะไปเริ่มถึงปัญหาและวิธีทำงานกับ PDF ผมขออนุญาติ พามาทำความเข้าใจประเภท PDF ใน session นี้ กันก่อนฮะ เพราะหลังจากนี้ จะพูดถึงทั้งสองแบบ ปนปนๆ กันไป
ประเภทของ PDF ใน Session นี้
1.) Digital PDF
- คุณฟีนให้คำนิยามว่า มันคือ PDF ที่เป็นรูปแบบ Graphic เวลาเรา Highlight บน PDF มันจะสามารถ Highlight ตัวอักษร หรือรูป ได้
- ถ้าเป็นลักษณะนี้ เราสามารถใช้ Library ในการดึงข้อมูล Graphic ออกมาได้เลย เช่น PymuPDF
2.) Scanned PDF
- คุณฟีนให้คำนิยามว่า มันคือ PDF ที่ถูกสแกนเป็นรูปเข้ามา PDF แบบนี้เวลาเราพยายาม Highlight มันจะทำไม่ได้
- ถ้าเป็นแบบนี้ อาจจะจำเป็นต้องใช้ OCR (Optical Character Recognition) ในการดึงข้อความ หรือ Object Detection ในการดึงรูปหรือตารางออกมา
Problems with PDF
คุณฟีนแชร์แชร์ให้ฟังว่าใน session นี้เราจะพูดถึงข้อมูล 3 ประเภท ที่อยู่ใน PDF คือ
- Image
- Table
- Text
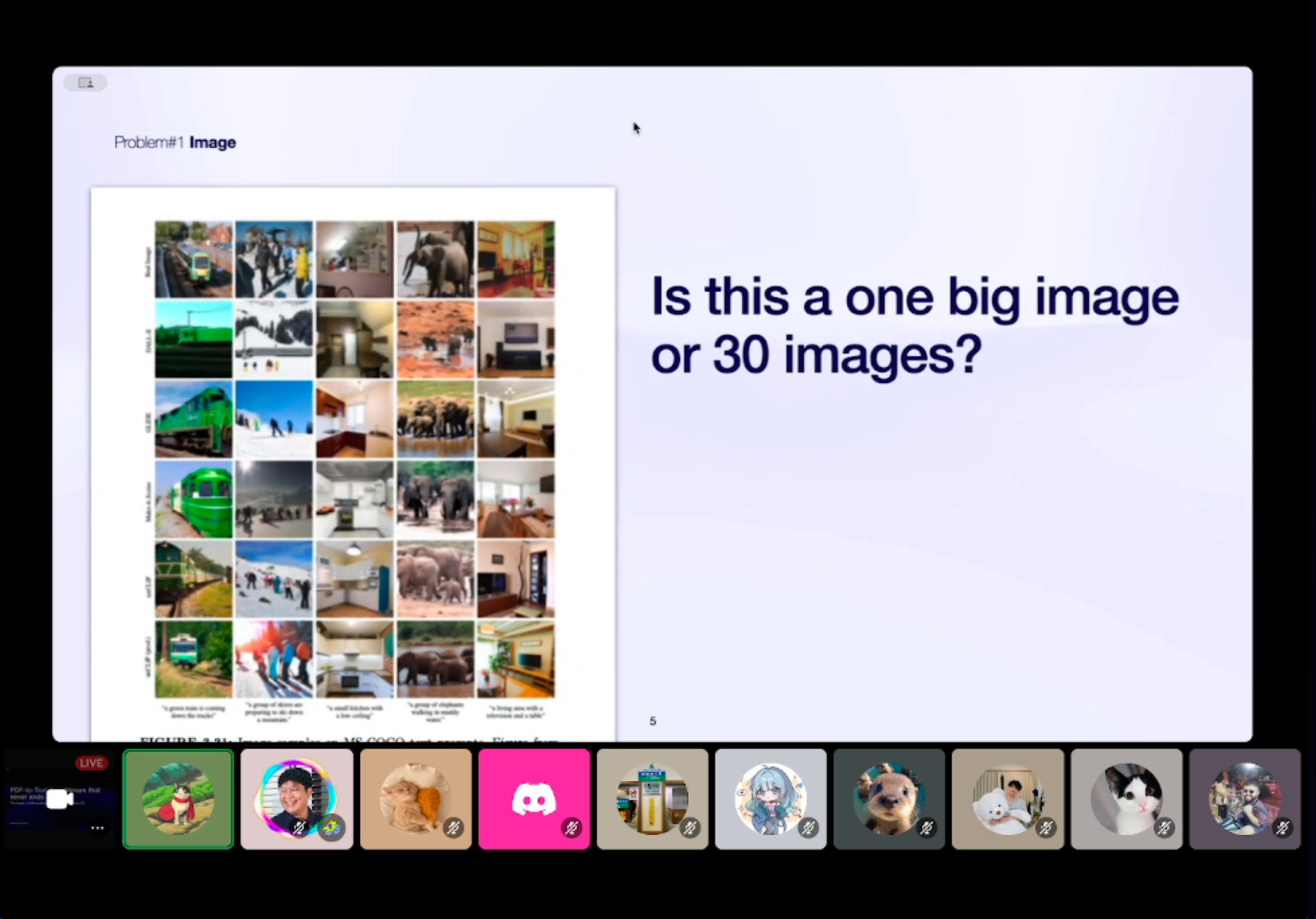
Problem with Image
เปิดกันที่ Case แรกครับ รูปภาพ หลัก ๆ ที่คุณฟีนแชร์ คือ แตกต่างกันที่ประเภทของ PDF ว่าเป็น Digital หรือ Scanned
ซึ่งถ้าเป็น Digital เราก็ใช้ Library ดึงรูปภาพออกมาได้เลย เช่น PyMuPDF
import fitz
pdf_file = fitz.open(FILE_PATH)
for page in pdf_file:
images = page.get_images()แต่ถ้าหากว่าเป็น Scanned เราก็อาจจะต้องใช้ Object Detection ดึงออกมาฮะ เราก็อาจจะเจอปัญหาอย่างในรูปข้างล่างฮะ ว่า เวลาเห็นรูปติด ๆ กันแบบนี้ เราควรจะมองเป็นรูปใหญ่ รูปเดียว หรือ มีหลายรูปแยกกัน ซึ่งตรงนี้ทำยังไงได้บ้าง มีอะไรให้ใช้บ้าง ไปดูกันที่ Solutions ด้านล่างสุดฮะ
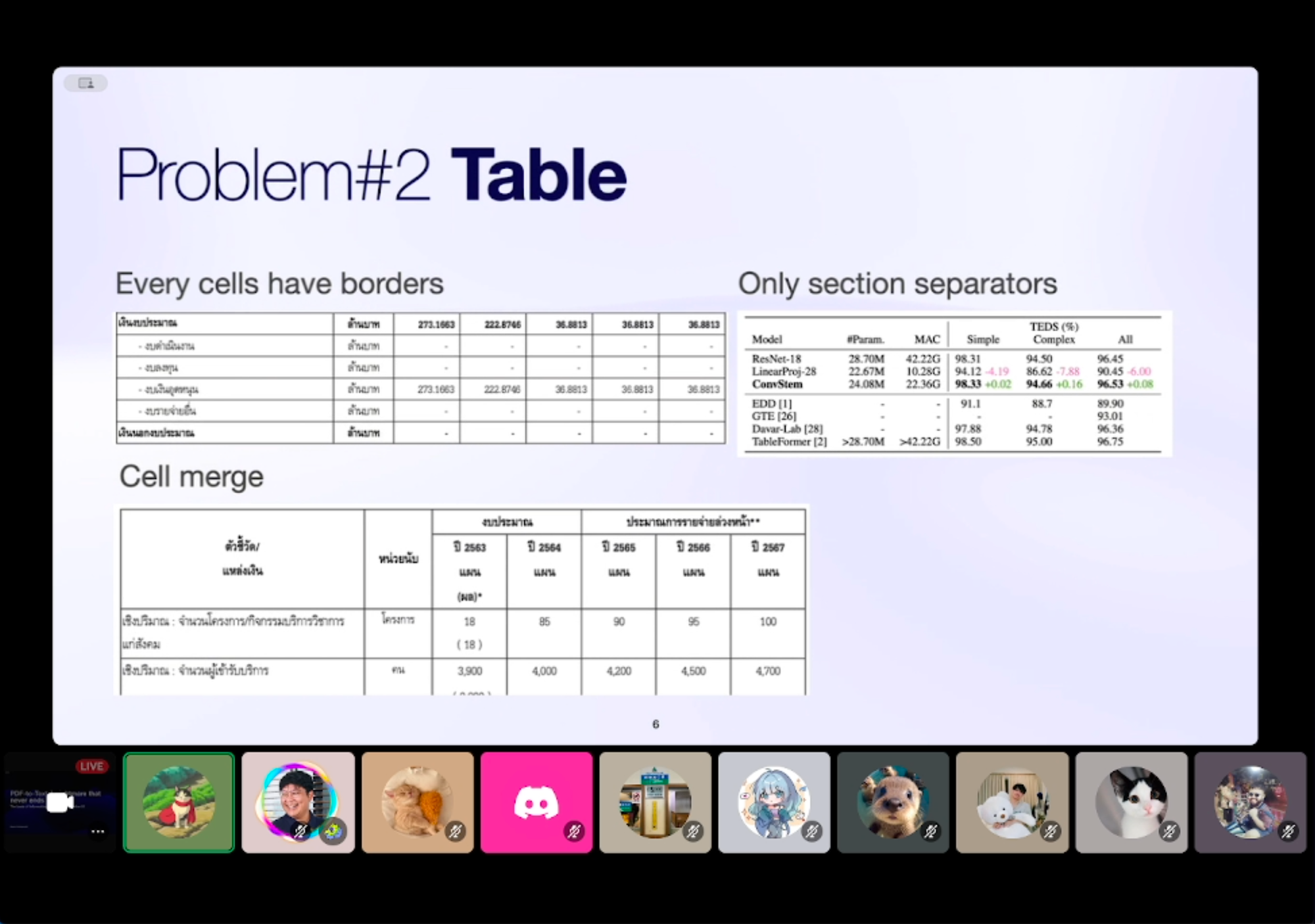
Problem with Table
ถ้าข้อมูลที่เข้ามาเป็น Digital ก็เช่นเดียวกันฮะ ใช้ Library อย่าง PyMuPDF ก็ได้
import fitz
pdf_file = fitz.open(FILE_PATH)
for page in pdf_file:
tables = page.find_tables()แต่!! ตารางก็มี Challenge อยู่ที่รูปแบบของมันฮะ เช่น
1. Only section separators ในรูปเราจะเห็นว่ามันไม่ได้มีเส้น แบ่ง cell, หรือแบ่ง row มาให้ตลอด นั่นแหละว่าถ้าเราเขียนด้วย PyMuPDF มันอาจะดึงออกมาตรงๆ ไม่ได้ อาจจะต้องมีการเขียนโค้ดเพื่อคำนวนตำแหน่ง x,y ของ ข้อความเพิ่มเติม เพื่อแยก row, columns
2. Cell merge ก็เป็น Challenge เช่นกัน เพราะ ข้อความใน 1 column อาจจะมีตำแหน่ง x,y คร่อมอยู่ 2 column และเป็นเหมือนกันกับ Row
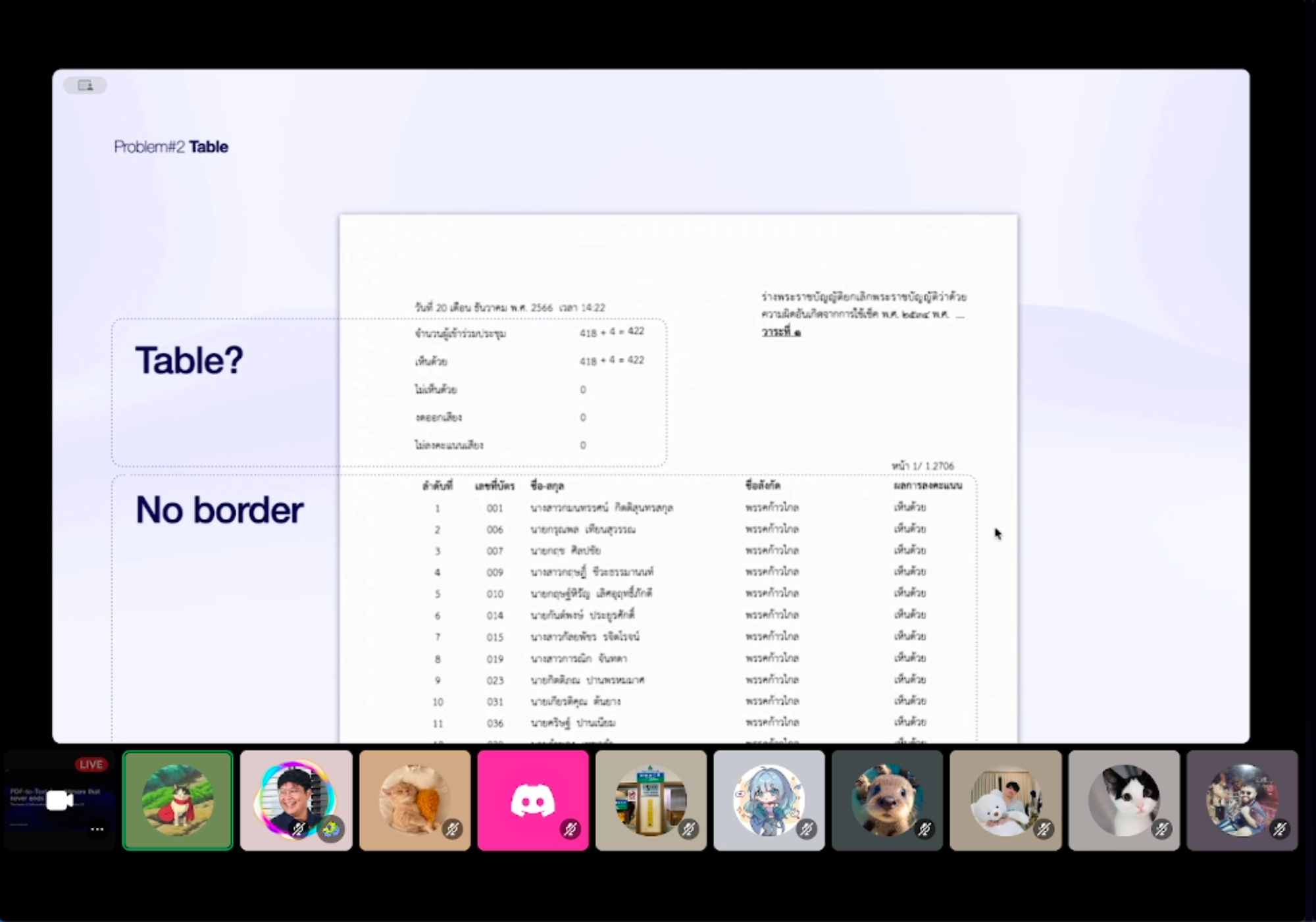
3. No border 🙅 - ตารางที่ไม่มีเส้นเลย อย่างตรงนี้ คุณฟีนแบบว่าใช้วิธีการดึงตำแหน่งตัวอักษรออกมาให้หมดก่อน แล้วค่อยไปหาว่า เส้นแบ่ง column และ row อยู่ตรงไหน
4. Tree table 🌲 - เคสนี้คือ แผนงานของ row ถัดมา เป็นตัวลูก ของ row ข้างบนแต่ว่าตำแหน่งของข้อความในแกน X อยู่ตรงกัน

Problem with Text
อีกเช่นเคยฮะ ถ้าเป็น Digital เราก็ดึงได้ เราสามารถดึงตัวหนาตัวบาง รวมไปถึง fontFamily ได้ด้วย แต่เราก็อาจจะเจอ Challenge ต่อไปนี้ฮะ
import fitz
pdf_file = fitz.open(FILE_PATH)
for page in pdf_file:
text = page.get_text()1. ตัวอักษรที่เป็น Vector ไม่ใช่ตัวอักษร 😮 - เคสนี้คุณฟีนบอกว่า ถ้าเราดึง text ได้ก็ดึงเลย แต่ถ้าดึงไม่ได้เรา assume ว่าอาจจะเป็น vector ก็ใช้ OCR ในการดึงเพิ่มเติมออกมา
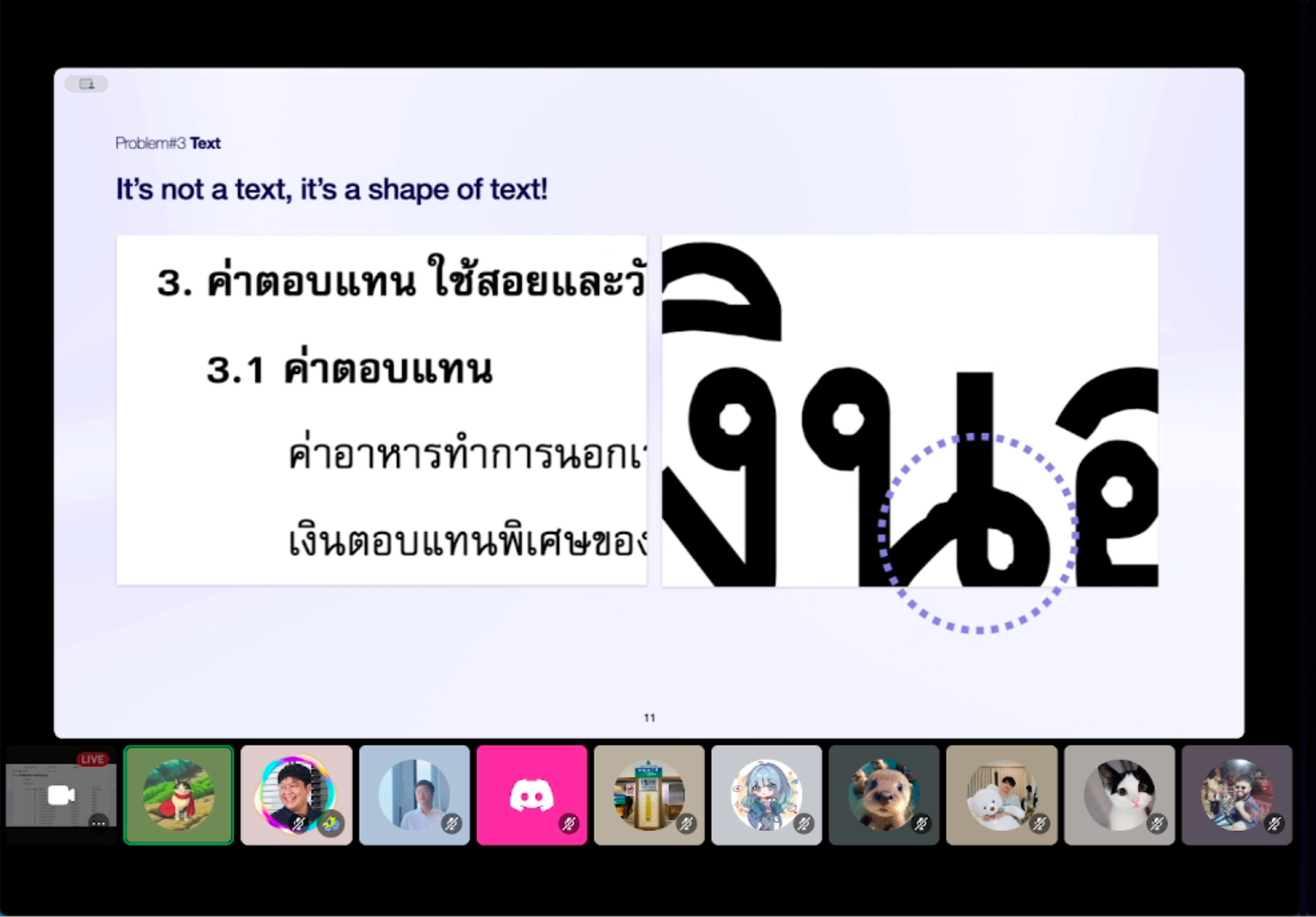
2. สิ่งที่เห็นไม่ใช่สิ่งที่เป็น 👁️ - เคสนี้คุณฟีนเจอว่ามันมีตัวอักษร สีขาว ซ่อนอยู่ วิธีการที่คุณฟีนใช้คือ เราอาจจะเช็คจากสีของตัวอักษรก็ได้ หรือทำ OCR ไปเลยก็ได้
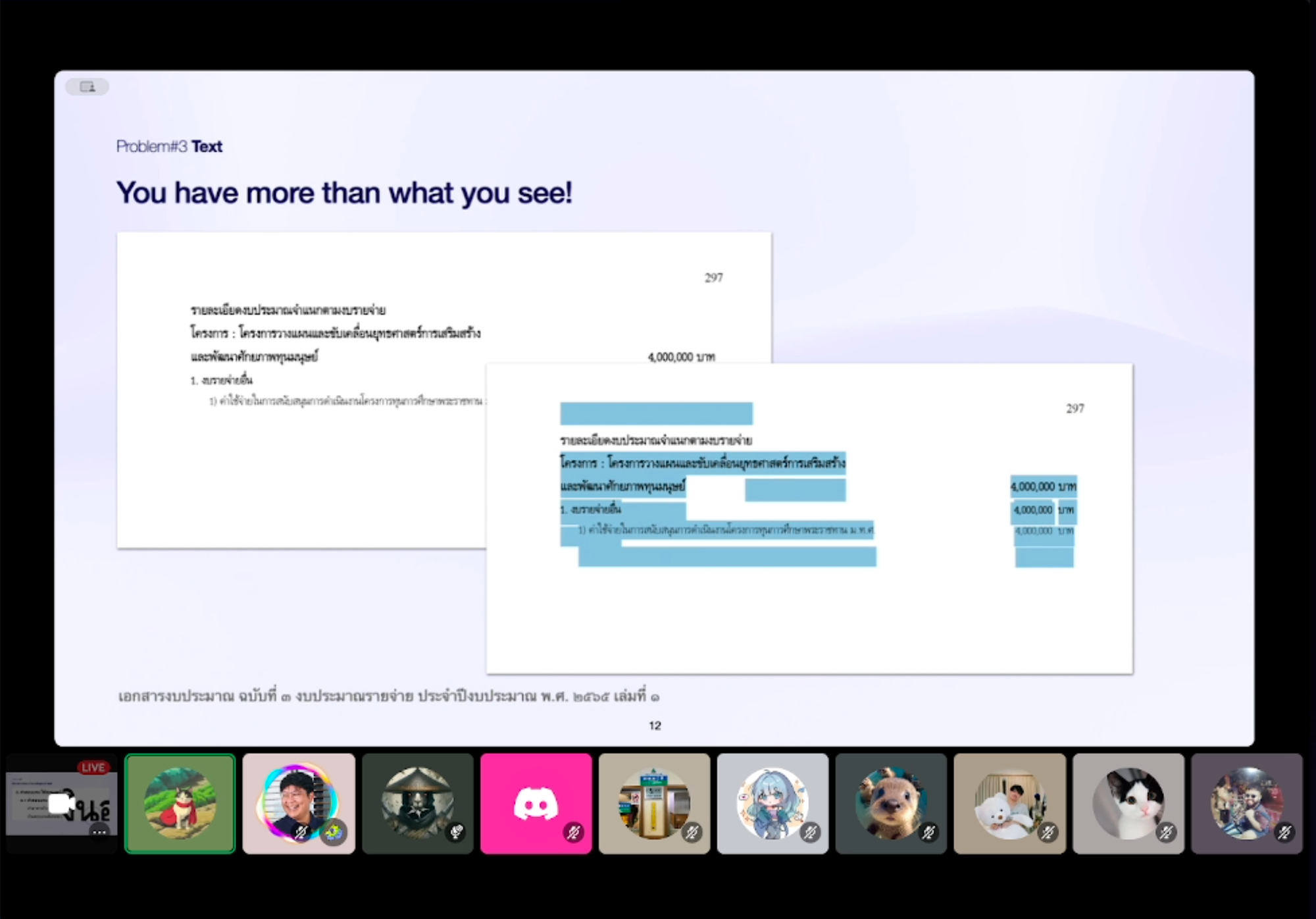
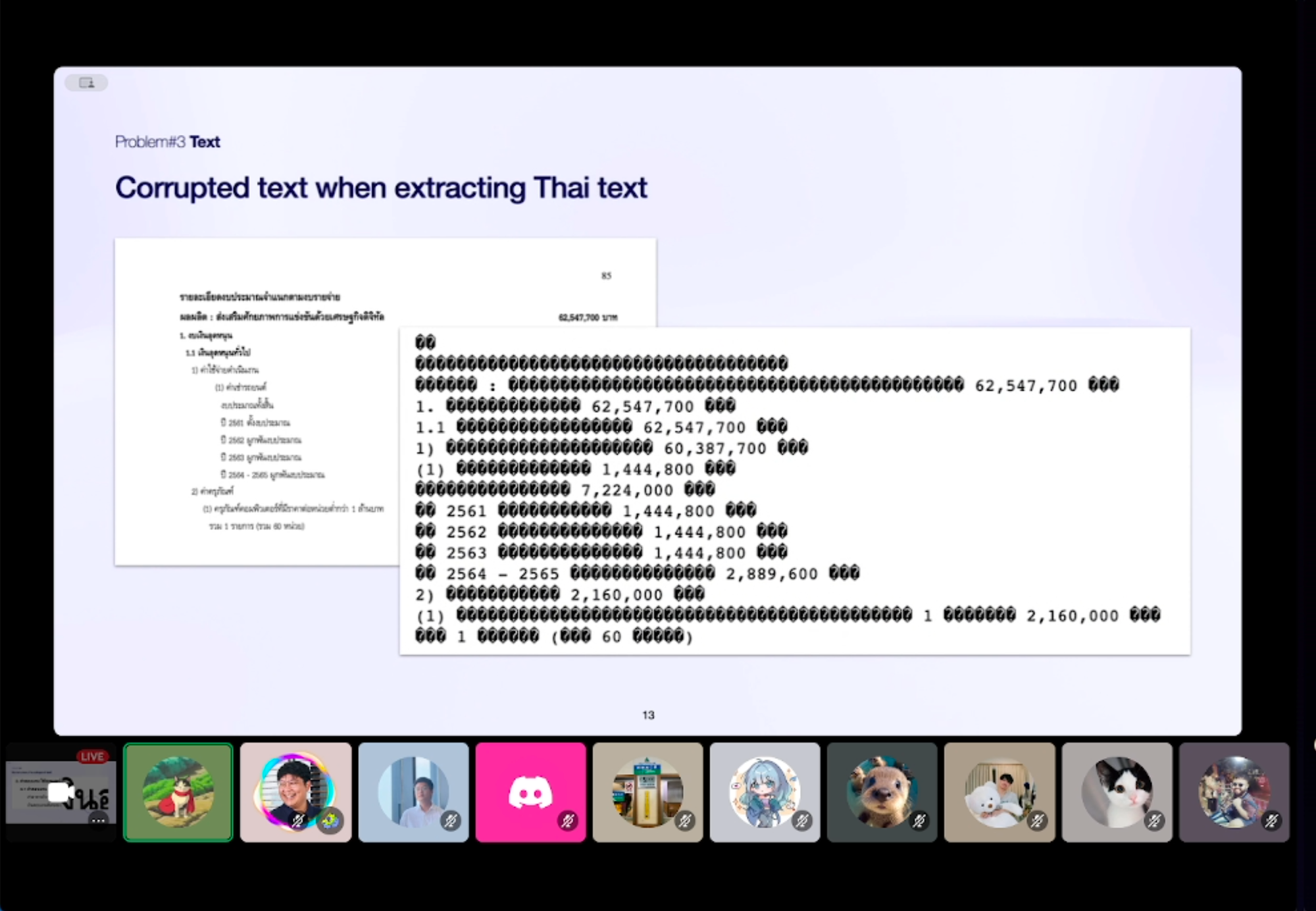
3. Corrupted text 👽 - ถ้าเจอนิดหน่อยๆ เราอาจจะใช้ Language Model เล็กๆมาช่วย correct ให้ถูกได้ แต่ถ้าเจอแบบในรูปที่แทบจะ corrupted ทั้งหมดเลย ก็อาจจะต้องใช้ OCR เข้ามาช่วย
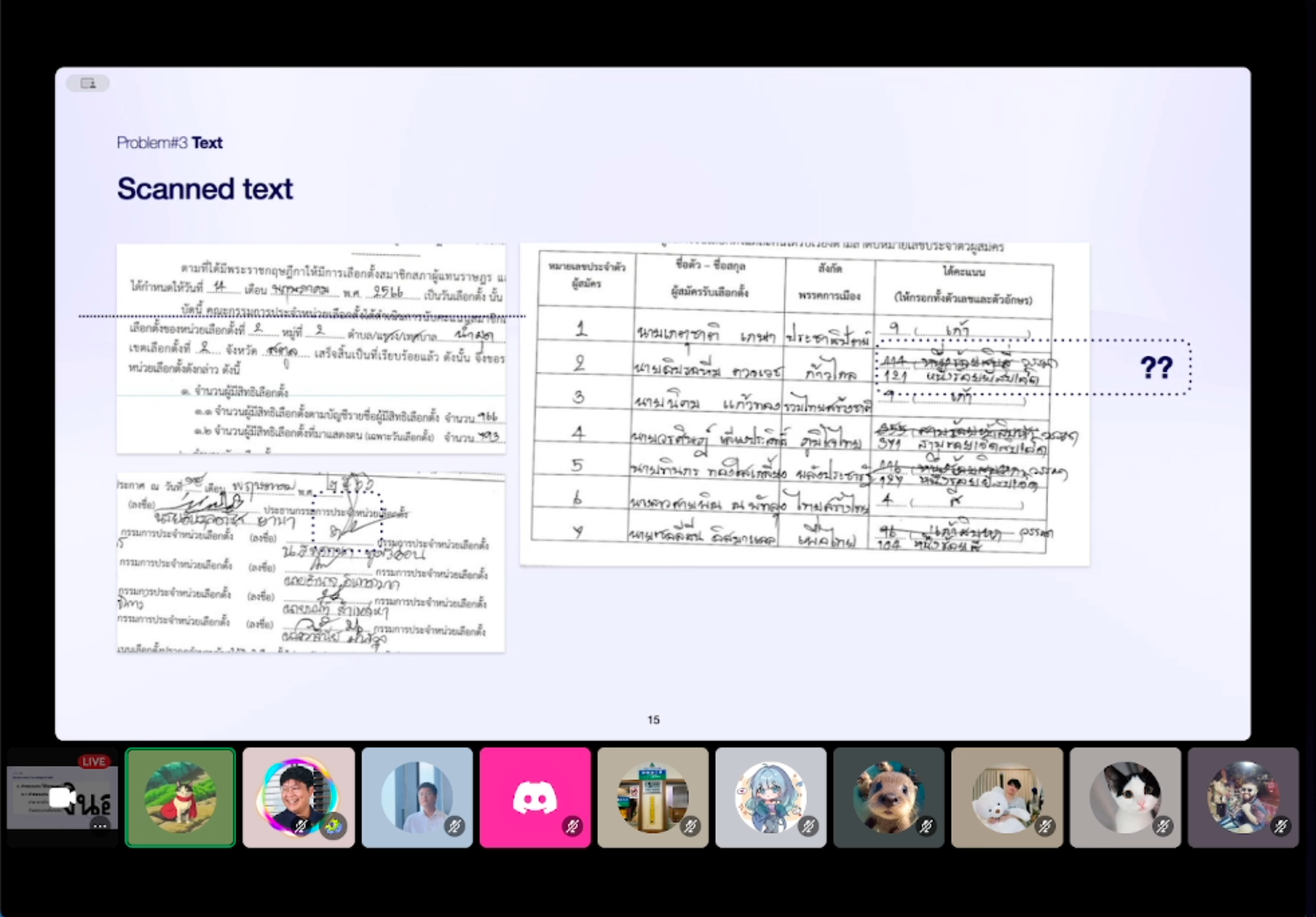
แล้วถ้าเป็นพวก Scanned text เราจะเจอปัญหาอะไรบ้าง คุณฟีนแชร์มาบางตัวอย่างฮะ
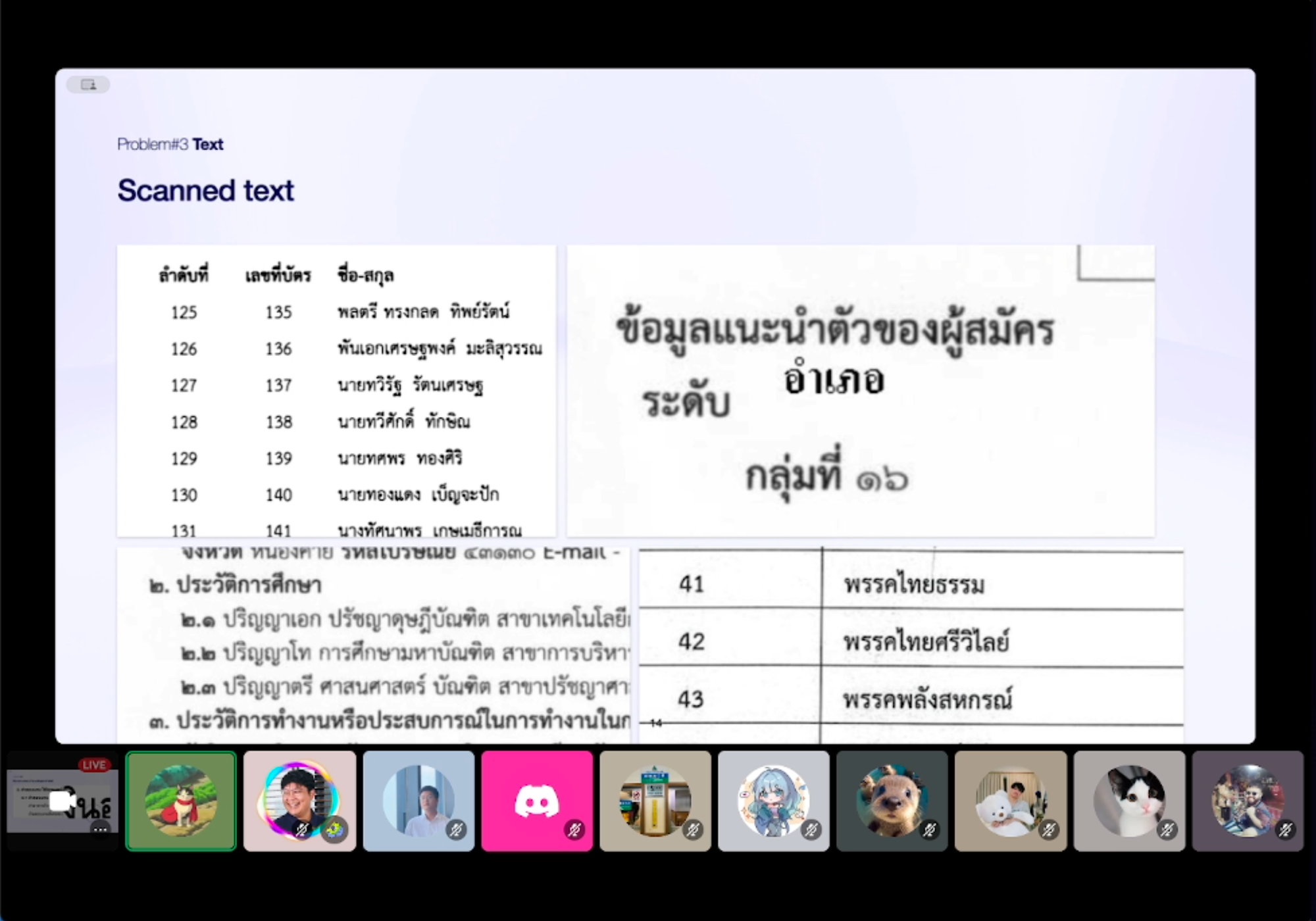
1. เหมือนว่าจะอยู่คนละบรรทัด 👀 - จากภาพ "ระดับ อำเภอ" มองด้วยตาก็น่าจะอยู่บรรทัดเดียวกัน ตรงนี้เราก็ต้องหาวิธีถอดตำแหน่งออกมาให้อยู่ในบรรทัดเดียวกัน
2.) บรรทัดเอียง 🌀 - วิธีการเราอาจจะลองทำ clustering โดยใช้แกน x,y เป็น feature เพื่อหาข้อความที่อยู่ในบรรทัดเดียวกัน
3. ลายเซ็น, ปั้มตราประทับ - อันนี้ก็เจอได้บ่อยครับ
4. ขีดฆ่า - อันนี้ก็เจอได้บ่อยเช่นกันครับ ซึ่งอาจจะต้องใช้วิธี object detection ในการจัดการ
Solutions
คุณฟีนนำเสนอ solution หลายตัวอยู่ฮะ
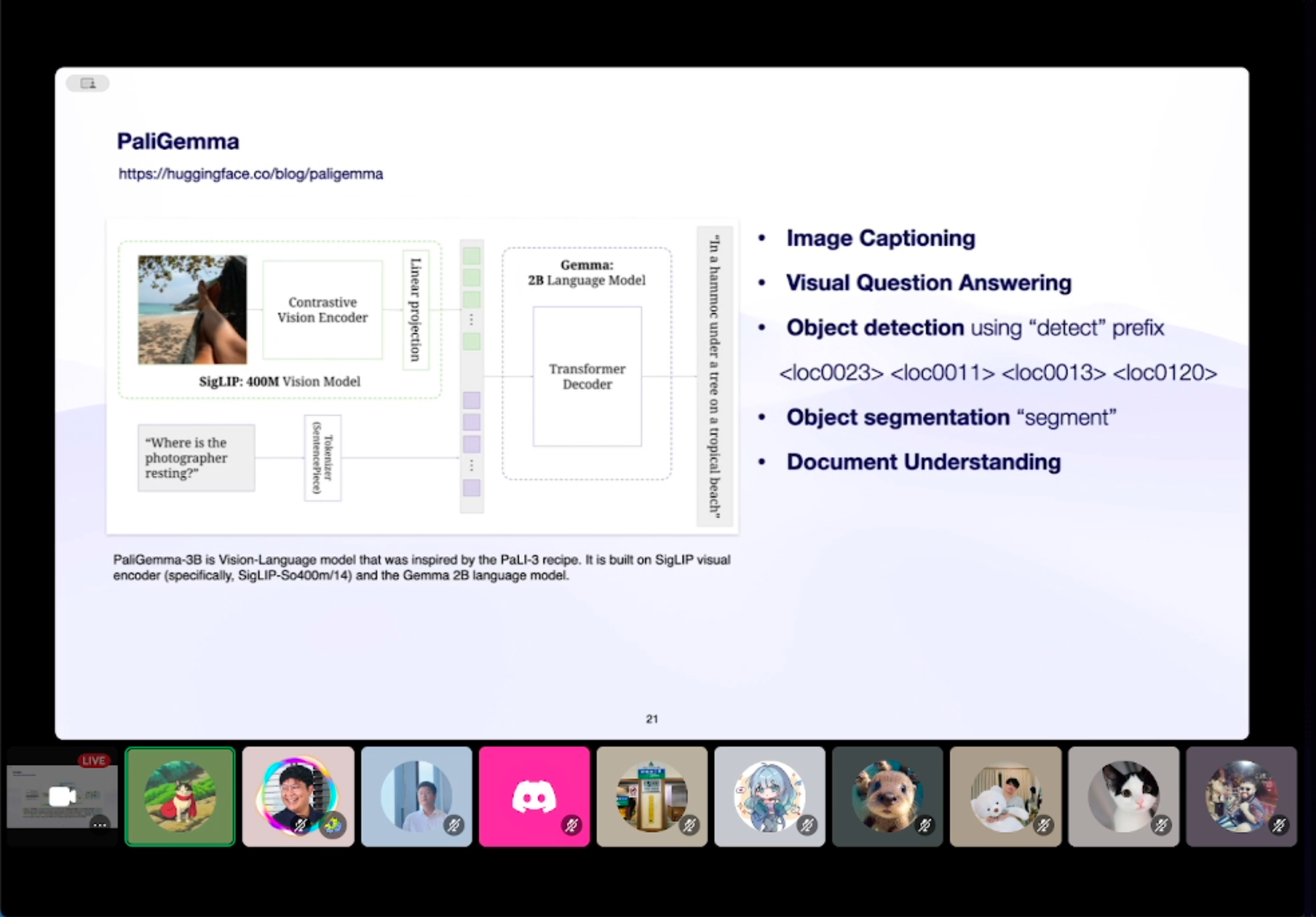
ตามไปดูตามไปฟังกันได้ใน Youtube นะครับ วินาทีที่ 18:38
Conclusion
สุดท้ายนี้ คุณฟีนจบด้วยสไลด์ที่ว่า "PDF trauma is real" 🤣 และก็หวังว่าทุกคนที่เข้ามาฟังใน Live, ดู Record หรือ อ่าน Blog ตัวนี้ จะได้ประโยชน์ไม่มากก็น้อยนะครับ
ถ้าใครอยากพูดคุยเพิ่มเติม หรือมีอะไรอยากจะเสนอเพิ่ม ก็ตามมาคุยกันได้ที่ GenAI Engineer Thailand Discord Group นะคร้าบ ขอบคุณครับ 👋

Additional Resource
- FixThaiPDF - จากน้องต้นตาล ผู้พัฒนา PyThaiNLP ครับ