RAG คืออะไร


RAG ย่อมาจาก Retrieval Augmented Generation, พูดง่าย ๆ มันคือการให้ LLM เราทำข้อสอบแบบ Open-book, เปิดหนังสือดูได้
RAG ประกอบด้วย 3 ขั้นตอนหลักๆ ดังนี้
- Retrieve - ค้นหาข้อมูลที่เกี่ยวข้องกับคำถามจากฐานข้อมูลหรือ knowledge base
- Augment - นำคำถามและข้อมูลที่เกี่ยวข้องมาสร้างเป็น prompt
- Generate - ส่ง prompt ให้ LM เพื่อสร้างคำตอบ
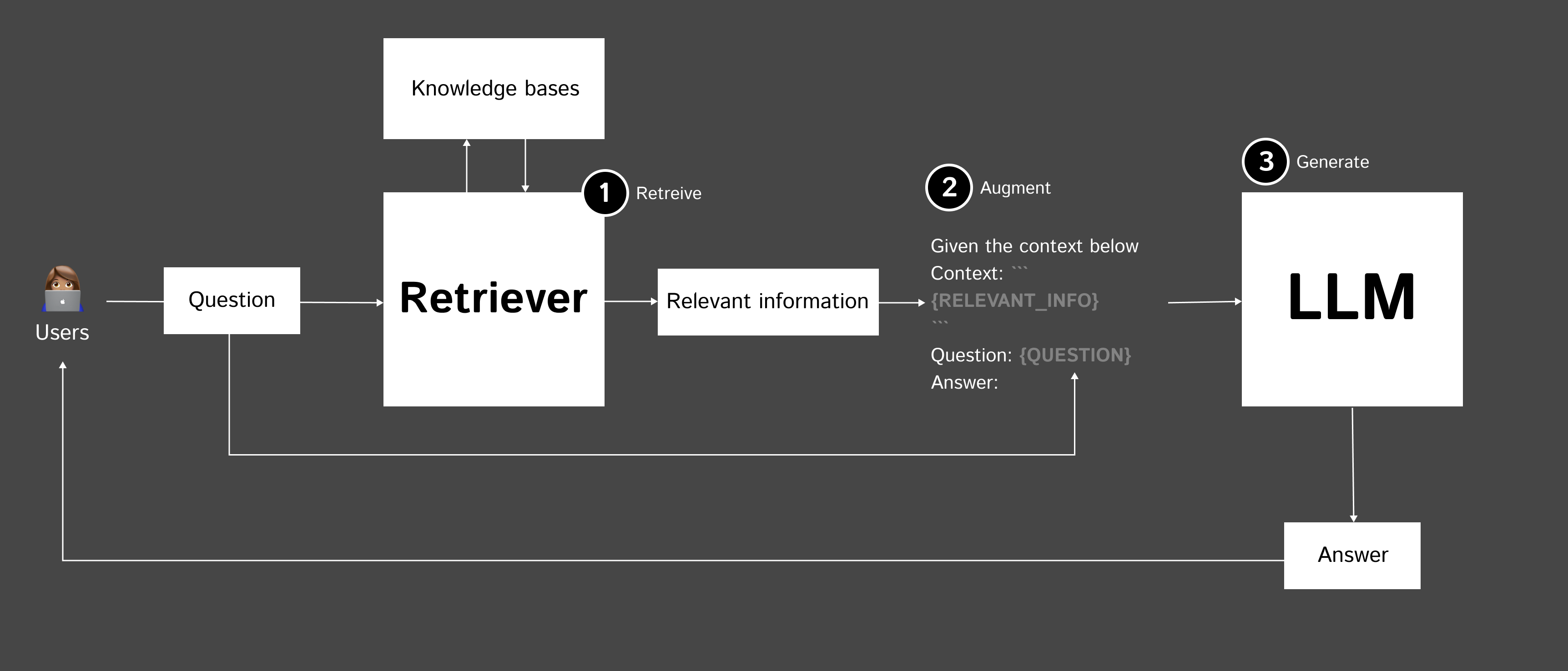
ตัวอย่างจาก: Retrieval augmented generation: Keeping LLMs relevant and current
แบบไม่มี RAG
RAG can refer to several different things depending on the context. Here are a few common meanings:
1. Red, Amber, Green (RAG): In project management and reporting, RAG is a color-coding system used to quickly convey the status or health of a project or task.
2. RAG Analysis: This is a method used in risk assessment or decision-making. It involves categorizing risks or options as Red, Amber, or Green based on their level of severity, impact, or desirability. It helps prioritize actions or choices.
3. Random Access Generator (RAG): In some technical contexts, RAG might refer to a system or algorithm that generates random access patterns or data, often used in computer science or information retrieval.
4. Resource Allocation Graph (RAG): In the context of operating systems and computer science, a Resource Allocation Graph is used for deadlock detection. It's a directed graph that represents resource allocation and request relationships among processes in a system.
แบบ ใช้ RAG
RAG, or retrieval augmented generation, is a method introduced by Meta AI researchers that combines an information retrieval component with a text generator model to address knowledge-intensive tasks. Its internal knowledge can be modified efficiently without needing to retrain the entire model. Would you like more details on this?
Background
โดยปกติ เวลาใช้งาน LLM เรามักจะใช้ Prompt บอกให้ LLM ทำในสิ่งที่เราต้องการ
Question: What is RAG?
Answer:แต่คำตอบที่ได้ ก็จะขึ้นอยู่กับข้อมูลที่ LLM ตัวนั้นใช้เรียนรู้ บ้างก็เก่าบ้าง บ้างก็ไม่เกี่ยว หรือบ้างก็อาจจะ Generic เกินไป หรือบางที ตัวก็มั่วไปเลย (Hallucination)
วิธีการแก้
- เราสามารถนำ LLM มาเรียนเพิ่ม (Finetuning) ก็ได้ ซึ่งอาจจะใช้เวลา และมีราคาพอสมควร
- หรือเราจะใส่ Context เข้าไปใน Prompt แล้วบอกให้ LLM ตอบคำถามเราโดยใช้ Context ที่เราใส่เข้าไปให้
Context อาจจะเป็นข้อมูล Wikipedia, ข้อมูลจาก website, จาก PDF หรืออะไรก็แล้วแต่ใส่เข้าไป
Given the context below, answer the following question
Context: ```
{CONTEXT}
```
Question: What is RAG
Answer: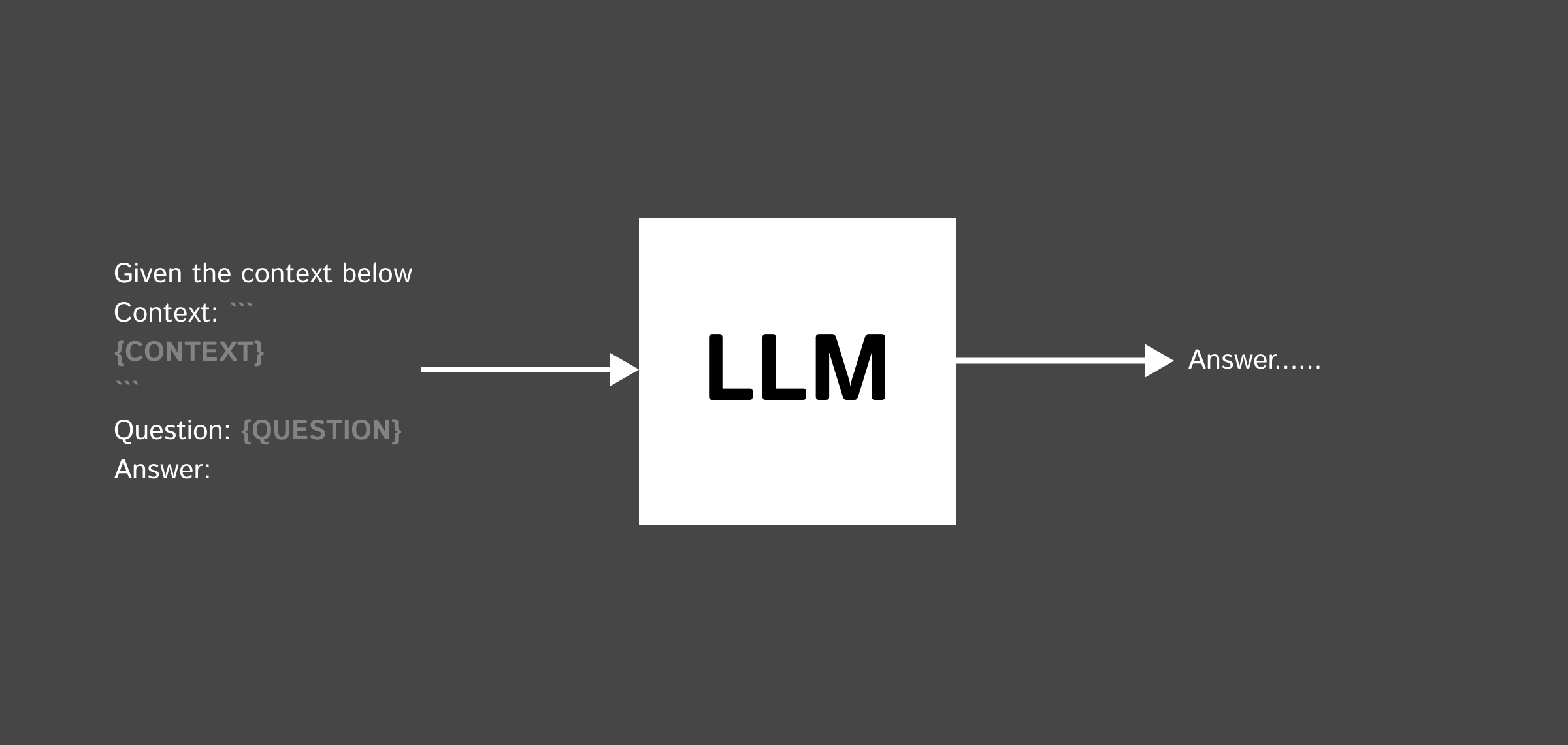
แต่เมื่อ เราต้องการให้มันตอบคำถาม จากข้อมูล PDF 100 หน้าที่เรามี หรือ ข้อมูลจากหนังสือ, หรือ wikipedia
RAG ช่วยแก้ปัญหาหลักๆ 2 อย่างของการใช้ LLM ตอบคำถามโดยตรง นั่นคือ
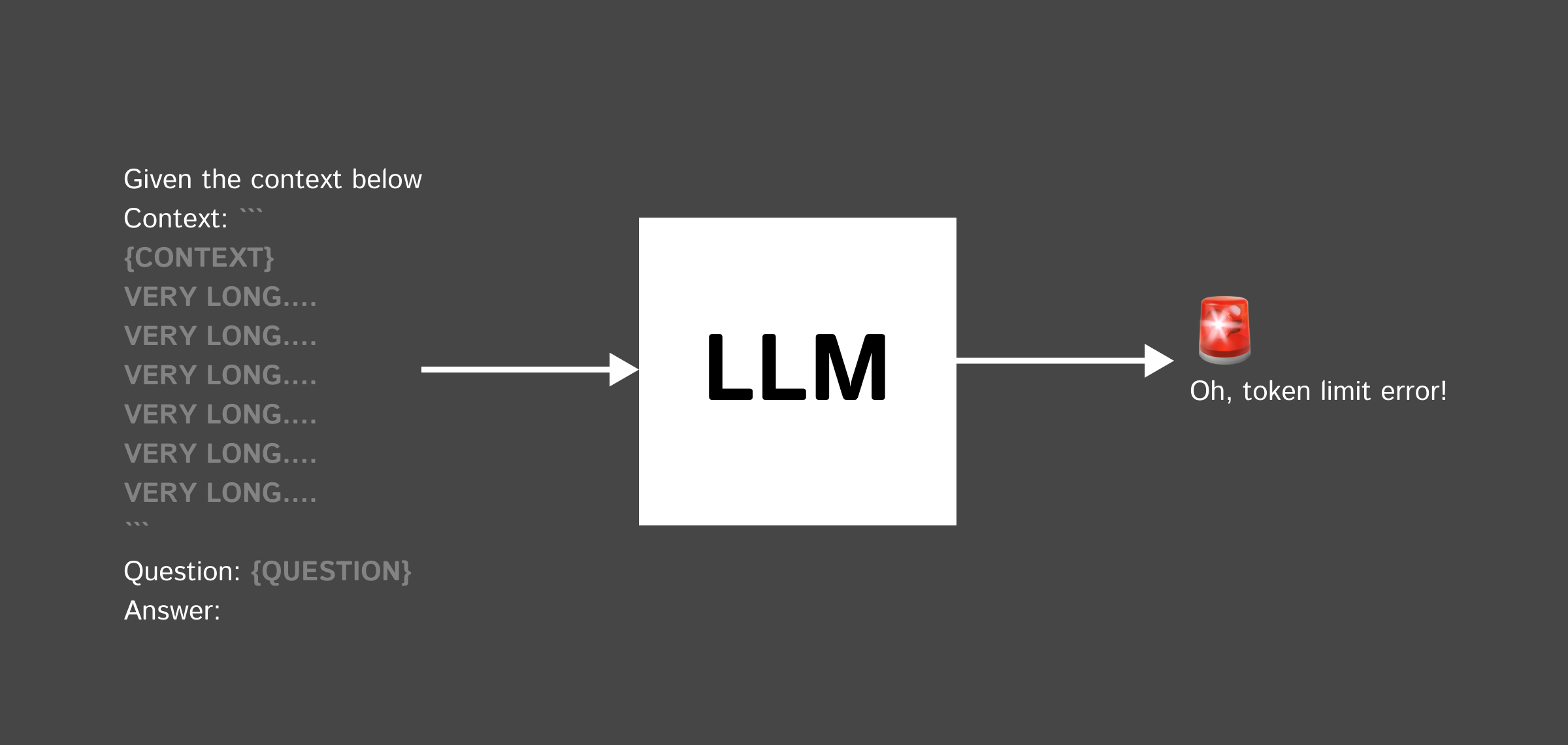
- Context มีขนาดจำกัด - LLM ส่วนใหญ่รองรับ token ได้จำนวนจำกัด ทำให้ไม่สามารถใส่ context ยาวๆได้
- ข้อมูลหายไประหว่างทาง - เมื่อ context ยาวเกินไป LM มักจะลืมเนื้อหาตรงกลางๆไป ทำให้ตอบคำถามได้ไม่ดี (Loss in the middle)
Context มีขนาดจำกัด
งั้นก็ง่ายหน่ะสิ แค่ใช้ LLM ที่รองรับ token เยอะๆ ก็พอไหมนะ?
คำตอบคือก็ทำได้ครับ แต่ก็จะมีค่าใช้จ่ายเพิ่มขึ้นมานั่นเอง เช่น
| Models | Max Tokens | Input - $/M tokens | Output - $/M tokens |
|---|---|---|---|
| gpt-4 | 8,192 | $30 | $60 |
| gpt-4-32k | 32,768 | $60 | $120 |
| gpt-3.5-turbo-1106 | 16,385 | $1 | $2 |
| gpt-3.5-turbo-instruct | 4,096 | $1.5 | $2 |
Reference: OpenAI Token Limit - Scriptbyai, OpenAI Pricing - as of March 17th
Token คืออะไร?
ข้อมูลหายไประหว่างทาง
ไม่ใช่เพียงแค่ จะส่งผลต่อราคาเท่านั้น เวลาที่ Context มีขนาดยาว ๆ ก็อาจทำให้เกิดปัญหา ต่อมาได้ คือ LLM จะลืม เนื้อหาตรงกลาง
ดังนั้นเราเลยต้องมีวิธีในการเลือก Context ที่เกี่ยวข้อง เพื่อให้ LLM ใช้ในการตอบคำถามนั้น ๆ ซึ่ง RAG สามารถช่วยตรงนี้ได้ครับ
แถมก่อนไปต่อ
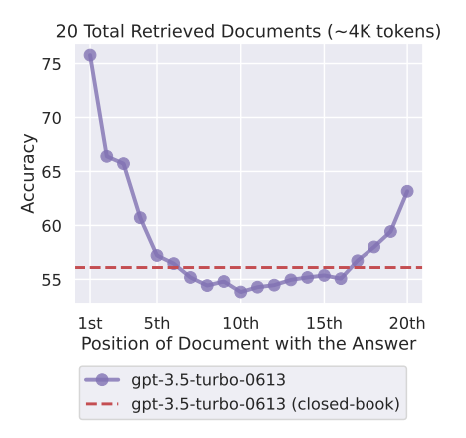
Needle in a haystack test - งมเข็มในมหาสมุทร (กองหญ้า?)
เป็นหนึ่งในวิธีการทดสอบ ว่าตัว LLM มีความสามารถในการหาคำตอบ (needle) ที่ซ่อนอยู่ในข้อมูล (haystack) ได้ดีแค่ไหน - ไม่แน่นะครับ อนาคต LLM อาจจะถูกพัฒนาไปจนถึงจุดที่เก่งมาก ถูกมาก, เทพมาก จนไม่จำเป็นต้องใช้ RAG อีกต่อไป...
Pressure Testing GPT-4-128K With Long Context Recall
— Greg Kamradt (@GregKamradt) November 8, 2023
128K tokens of context is awesome - but what's performance like?
I wanted to find out so I did a “needle in a haystack” analysis
Some expected (and unexpected) results
Here's what I found:
Findings:
* GPT-4’s recall… pic.twitter.com/nHMokmfhW5
RAG ทำยังไง
คำถามถัดมา แล้ว RAG มันทำยังไงกันล่ะ ตัวอย่างง่าย ๆ แบบ Copy-and-paste แล้วใช้ได้เลย
from langchain.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://www.promptingguide.ai/techniques/rag")
index = VectorstoreIndexCreator().from_loaders([loader])
index.query("What is RAG?")Reference: Retrieval augmented generation: Keeping LLMs relevant and current
ดูกันเร็ว ๆ สิ่งที่โค้ดข้างบนทำ คือ
- โหลดข้อมูลตั้งต้น เช่น จากเว็บไซต์
- เก็บลงใน vector store โดยแบ่งข้อความเป็นส่วนๆ แล้ว embed เป็น vector
- ส่งคำถามให้ vector store ค้นหา context ที่เกี่ยวข้อง
- ส่ง context พร้อมคำถามให้ LM เพื่อสร้างคำตอบ
เพิ่มเติมจากรูปข้างบน เราจะเห็นว่า ก่อนที่เราจะถามคำถามได้ เราจำเป็นต้องเตรียมข้อมูลก่อน เราเรียกว่า Indexing
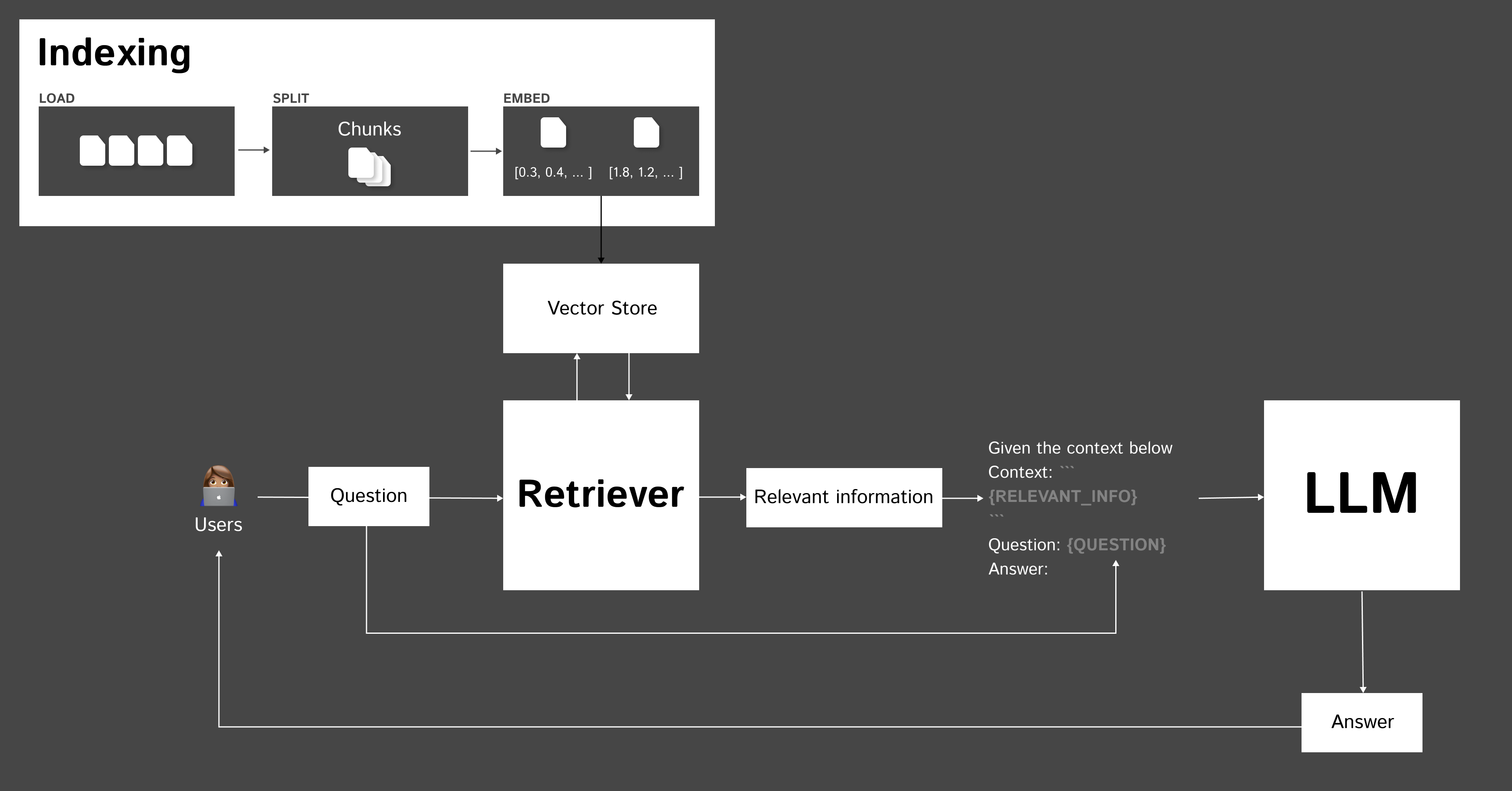
ตัวอย่างเบื้องต้น สำหรับเพื่อการเริ่มต้น เรายังสามารถ improve RAG ปรับนู่นนี่ เพื่อให้มันทำงานได้อย่างมีประสิทธิภาพได้อีกหลายรูปแบบนะครับ
Modular RAG คือ
เอาล่ะครับ มาถึงตรงนี้ หลายคนอาจจะเริ่มงงๆแล้วสินะ ว่าเอ๊ะ ขั้นตอนการใช้ RAG มันก็ดูไม่ยากเลย แต่ทำไมเขาถึงบอกว่ามันเป็นเรื่องที่ซับซ้อนล่ะ? 🤔
 Phasathorn Suwansri
Phasathorn Suwansri
จริงๆแล้วเนี่ย RAG มันก็เหมือนกับเครื่องมืออื่นๆนั่นแหละครับ ถ้าเราอยากให้มันทำงานได้ดีเต็มประสิทธิภาพ เราก็ต้องปรับแต่งมันให้เข้ากับความต้องการของเรา
โชคดีที่ RAG มีการพัฒนามาระดับนึงจนตอนนี้เราสามารถแยกมันออกมาเป็น Modular RAG ที่แบ่งการทำงานออกเป็นส่วนๆ ไม่ว่าจะเป็น Indexing, Pre-Retrieval, Retrieval, Post-Retrieval, Generation หรือ Orchestration ซึ่งทำให้เราสามารถเลือกปรับแต่งแต่ละส่วนให้เหมาะกับงานของเราได้ สุดยอดไปเลย! 🎉

- Indexing - เอาข้อมูลตั้งตนลงไปใน database ยังไงให้ดีที่สุด
- Pre-Retrieval - หลังจาก user ถามมาแล้ว เราควรจะทำให้คำถามเข้าใจง่ายที่สุด ก่อนที่จะไปค้นหา
- Retrieval - ค้นหายังไงให้มีประสิทธิภาพสูงสุด
- Post-Retrieval - พอได้ผลลัพธ์มาแล้ว จะทำยังไงให้ได้ข้อมูลที่เกี่ยวข้องมากที่สุด
- Generation - ตอน LLM ตอบ, ทำยังไง ถึงจะตอบได้ถูกต้องที่สุด
- Orchestration - เราจะ control รูปแบบการทำงานของ RAG ยังไง ได้คำตอบแล้วต้องทำอะไรต่อไหม
การแบ่งการทำงานของ RAG เป็นโมดูลย่อยแบบนี้ ช่วยให้สามารถปรับแต่งและเพิ่มประสิทธิภาพในแต่ละขั้นตอนได้มากขึ้น เพื่อให้ระบบสามารถตอบคำถามได้แม่นยำและตรงจุดที่สุด รวมถึงเปิดโอกาสให้นำไปผสมผสานกับเทคนิคอื่นๆเพิ่มเติมได้อีกด้วย
บทความเต็มเขียนสรุปไว้ดีเลยครับ ตามไปอ่านกันได้ฮะ
- Modular RAG and RAG Flow: Part Ⅰ
- Modular RAG and RAG Flow: Part II
Phasathorn Suwansri
Conclusion
แต่เอาเข้าจริงๆ สิ่งสำคัญของการใช้ RAG ให้เกิดประโยชน์สูงสุด มันอยู่ที่การเลือกใช้มันให้ถูกที่ถูกทางต่างหากล่ะครับ เวลามีข้อมูลเยอะ ๆ การโยนเข้าไปใน Prompt ให้ LLM อย่างเดียวอาจจะไม่พอ RAG จะมาช่วยให้เราได้คำตอบที่แม่นยำ ตรงใจ และเกี่ยวข้องกว่าเดิมหลายเท่า
งานนี้ไม่ต้องสงสัยครับว่ามันจะกลายเป็นเครื่องมือสำคัญในการพัฒนา AI ให้ฉลาดขึ้นอีกระดับในอนาคตแน่ๆ (รึเปล่า?) ใครสนใจก็ลองศึกษา ทดลอง ปรับใช้ดูนะครับ
ท้ายนี้ ใครอ่านแล้วมีความคิดเห็นอะไรเพิ่มเติม, หรือเอา RAG ไป implement แล้วอยากจะแชร์อะไร สามารถติดต่อมาพูดคุยกันได้ครับที่ x.com/lukkiddd