LLM Application วัดผลยังไง
การประเมิน LLM มี 3 วิธี - Code-based, Human-based, และ LLM-based Grading เพื่อสร้างความไว้วางใจและแม่นยำ โดย Code-based ง่ายที่สุด, Human-based แม่นยำแต่ใช้เวลา, LLM-based ใช้ LLM ตัดสินแล้วเทียบกับผลของมนุษย์เพื่อปรับปรุง...


หลังจากที่เราผ่านช่วงระดมไอเดียและการทดลอง PoC เพื่อสร้าง Application โดยใช้ความสามารถของ LLM กันมาแล้ว จุดนึงเพื่อน ๆ หลาย ๆ คน น่าจะเริ่มมีคำถามว่า แล้วเราจะรู้ได้ยังไงว่าระบบที่เราทำขึ้นไปมันทำงานได้ถูกต้อง, ถ้าเราแก้ Prompt ผลลัพธ์ของ Application เรายังคงทำงานปกติอยู่ ในมุมมองของการพัฒนา Application หนึ่งสิ่งที่เราต้องทำแน่ ๆ คือ testing ตั้งแต่การ test ระดับ function ไปจนถึง ระดับภาพรวม
ยาวเกิ๊น;งั้นอ่านนี่
สรุปในบรรทัดเดียว: การประเมิน LLM Application มีอยู่สามวิธีหลัก: Code-based Grading, Human-based Grading, และ LLM-based Grading
ประเด็นสำคัญ:
- 🎯 Evaluation ช่วยสร้างความไว้วางใจให้กับทั้งทีมพัฒนาและผู้ใช้งาน เพื่อให้มั่นใจว่าระบบมีความน่าเชื่อถือและแม่นยำ
- 🧪 การให้คะแนนโดย Code-base Grading ทำได้ง่ายที่สุด เป็นวิธีการเขียนเหมือนกันกับ Software Development โดยเทียบจาก Example หรือ เทียบจาก Property (ความยาวอยู่ในจำนวนที่กำหนด, หรือ patterns ตรงตามต้องการ)
- 👥 การให้คะแนนโดยมนุษย์, Human-based Grading, ให้การประเมินที่แม่นยำแต่ใช้เวลามาก เหมาะสำหรับกรณีที่ซับซ้อนซึ่งการทดสอบอัตโนมัติอาจทำได้ยาก
- 🤖 การให้คะแนนโดย LLM, LLM-based Grading, ใช้ LLM เป็นผู้ตัดสินผ่านการให้คะแนน, Direct Scoring (0-5) หรือการเปรียบเทียบแบบจับคู่, Pairwise Comparison เพื่อจะให้ผลดีที่สุด เราจำเป็นต้อง เอาผลลัพธ์ของ LLM มาเทียบกับผลลัพธ์ของ Human แล้วแก้ Prompt ให้ผลลัพธ์ของทั้งสองฝั่ง Align กัน
- 🔍 การบันทึกและการติดตามเป็นสิ่งจำเป็นสำหรับการปรับปรุงอย่างต่อเนื่องโดยใช้ข้อมูลจากลูกค้าจริง
- 💡 เทคนิคต่างๆ สามารถเพิ่มประสิทธิภาพในการประเมิน เช่น การใช้ LLM ขนาดเล็กหลายตัวแทนที่จะใช้ตัวใหญ่ (e.g., GPT-4) หนึ่งตัว หรือการเพิ่มคำถามที่เฉพาะเจาะจงเช่น "don't overthink"
สำหรับ Application ที่มีการใช้งาน LLM อยู่เบื้องหลัง เราจะทดสอบมันได้ยังไง วันนี้ เราจะมาดูไอเดียคร่าว ๆ จากเหล่า Practitioner กันครับ
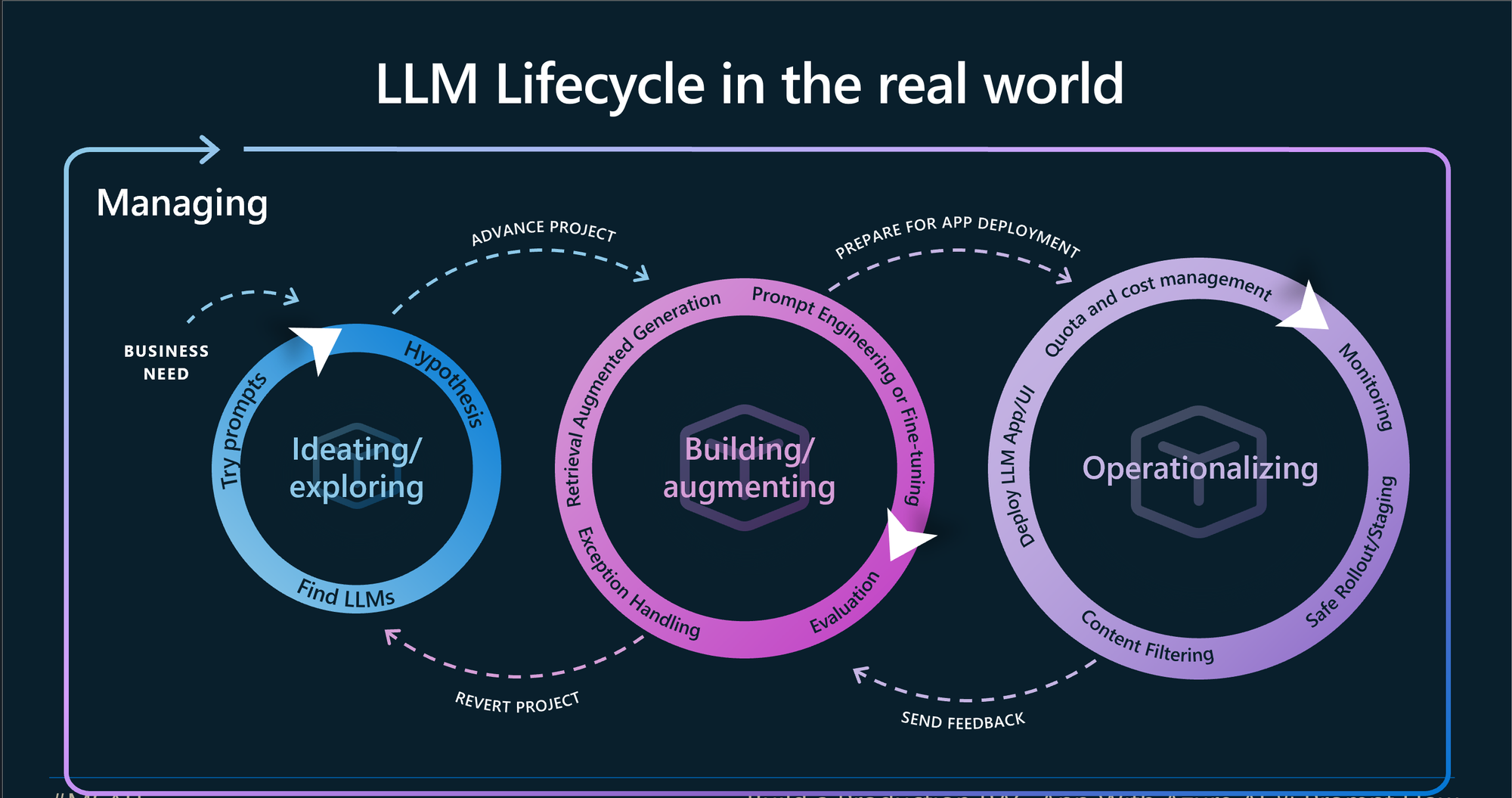
Outline
- Evaluation is about trust
- ประเภทของ Evaluation
- Code-based Grading
- Human-based Grading
- LLM-based Grading (w/ Human Alignment)
- How to get started
- Looking Ahead
Evaluation is about trust
Josh Tobin พูดไว้ได้ดีเลยฮะ ว่าการที่เรามี Evaluation ที่ดี ทำให้เรา Trust ในระบบของเรา มีสองกลุ่มหลักๆ ที่ต้อง Trust ในระบบของเราครับ 1) คือทีมที่ทำ 2) ผู้ใช้งาน
- ทีมที่เราต้องมั่นใจว่าเวลาเราแก้ไขอะไรบางอย่างไป เช่น การแก้ Prompt เรายังจะต้องเชื่อมั่นว่าระบบเรายังคงทำงานได้ปกติอยู่ หรือ Prompt ใหม่ที่แก้มา ใช้ Input tokens เยอะมากกว่าเดิมมากเลย มันแม่นกว่าเดิมรึเปล่านะ มันคุ้มไหมนะ ที่จะแก้ Prompt นี้
- ผู้ใช้งานก็ต้องมั่นใจว่า คำตอบที่ระบบเราตอบออกไปเชื่อถือได้ เช่น SQL ที่ Generate มา แล้วได้มาซึ่งคำตอบ ใช้ข้อมูลจาก Table ที่ถูกต้อง ไม่ต้องให้ User คอยตรวจสอบคำตอบตลอดว่าถูกไหมน้า
ประเภทของ Evaluation
แบ่งออกเป็น 3 ประเภทครับ
- Code-based Grading
- Human-based Grading
- LLM-based Grading (LLM-as-judge)
มาทำความเข้าใจกันไปทีละรูปแบบกันฮะ
1. Code-based Grading (Programatic)
หากเพื่อน ๆ ที่อ่านคุ้นเคยกับการทำ Software มาก่อนแล้ว ต้องเคยได้ผ่านการทำ Unit-test กันมาบ้าง ใช่ไหมฮะ Code-base Grading ก็คือลักษณะเดียวกันเลยครับ เราวัดผลลัพธ์ของ LLM โดยใช้วิธีการเขียนโปรแกรม
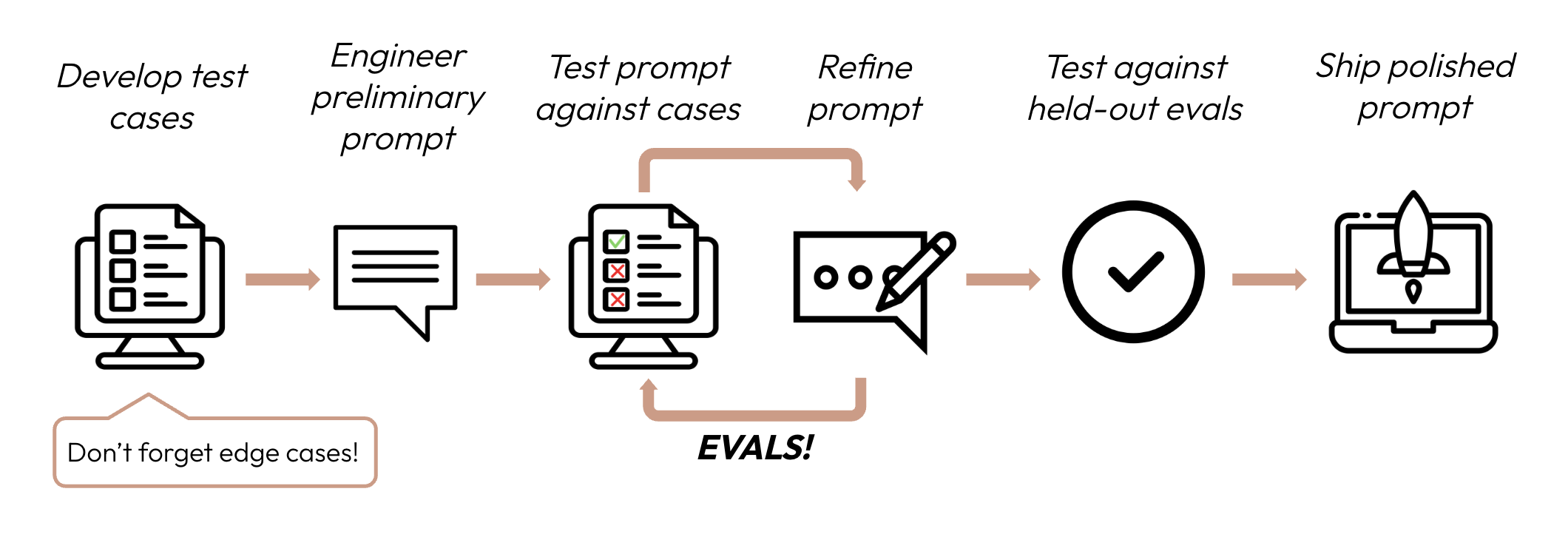
Example-based
รูปแบบนี้คือเรามีตัวอย่าง หรือ ผลลัพธ์ที่เราต้องการ สิ่งที่เราทำก็คือทดสอบว่ามันได้ผลลัพธ์ที่เราต้องการไหม เช่น ตัวอย่างนึง จาก Anthropic Prompt Evaluation ฮะ เค้ามีตัวอย่างของ input (animal_statement) และ expected output (golden_answer)
eval_data = [
{"animal_statement": "The animal is a human.", "golden_answer": "2"},
{"animal_statement": "The animal is a snake.", "golden_answer": "0"},
{"animal_statement": "The fox lost a leg, but then magically grew back the leg he lost and a mysterious extra leg on top of that.", "golden_answer": "5"},
{"animal_statement": "The animal is a dog.", "golden_answer": "4"},
{"animal_statement": "The animal is a cat with two extra legs.", "golden_answer": "6"},
{"animal_statement": "The animal is an elephant.", "golden_answer": "4"},
{"animal_statement": "The animal is a bird.", "golden_answer": "2"},
{"animal_statement": "The animal is a fish.", "golden_answer": "0"},
{"animal_statement": "The animal is a spider with two extra legs", "golden_answer": "10"},
{"animal_statement": "The animal is an octopus.", "golden_answer": "8"},
{"animal_statement": "The animal is an octopus that lost two legs and then regrew three legs.", "golden_answer": "9"},
{"animal_statement": "The animal is a two-headed, eight-legged mythical creature.", "golden_answer": "8"},
]Example from Anthropic Prompt Evaluation
ส่วน Prompt คือการให้ LLM ตอบมาว่า สื่งมีชีวิตที่ mention นี้มีกี่ขา
You will be provided a statement about an animal and your job is to determine how many legs that animal has.
Here is the animal statement.
<animal_statement>{animal_statement}</animal_statement>
How many legs does the animal have? Please respond with a numberExample from Anthropic Prompt Evaluation
หลังจากรัน script แล้วเค้าก็เอามาเทียบกันตรง ๆ เลยฮะ
def grade_completion(output, golden_answer):
return output == golden_answerExample from Anthropic Prompt Evaluation
หรืออย่างในบทความ Engineering Practices for LLM Application Development โดย Davin Tan และ Jessica Wang เค้าได้อธิบายพร้อมยกตัวอย่างไว้ให้ดูฮะ
ในโค้ดด้านล่าง เราต้องการให้ LLM ตอบ intent กลับมาเป็นค่าว่า "DELIVERY" แบบที่เราต้องการ
def test_delivery_dropoff_scenario():
example_scenario = {
"input": "I have a package for John.",
"intent": "DELIVERY"
}
response = request_llm(example_scenario["input"])
# this is what response looks like:
# response = {
# "intent": "DELIVERY",
# "message": "Please leave the package at the door"
# }
assert response["intent"] == example_scenario["intent"]
assert response["message"] is not NoneExample from Engineering Practices for LLM Application Development
ลองดูโค้ด test ตัวอย่างที่เค้าสร้างไว้ให้ได้ ที่นี่ ฮะ
Property-based
ส่วน Property-based คือการวัดคุณสมบัติครับ จากโค้ดชุดเดียวกันด้านบน property-based หมายถึง "message" จะต้องไม่เป็น None
เราสามารถทดสอบได้ในอีกหลายรูปแบบครับ เช่น
- Pattern Recognition - ใช้ Regular Expression ดูว่า มี เบอร์โทรศัพธ์ไหม มี Email ไหม หรือมี Pattern อะไรที่เราอยากให้มีรึเปล่า
- Semantic Matching - ใช้ Text Embedding มาช่วยหาว่า text สองชุด มี Semantic Matching กันมากแค่ไหน ถ้ามากกว่า Threshold ถือว่าผ่าน
- NLP Metrics - ใช้ Library เช่น textstat มาคำนวน Metric ทาง NLP เช่น Readability Score
textstat support แค่บางภาษา
อย่างตัวอย่างด้านล่างจาก Your AI Product Needs Evals - Hamel Husain เค้าเขียนทดสอบว่าต้องไม่มี UUID ในข้อความ
const noExposedUUID = message => {
// Remove all text within double curly braces
const sanitizedComment = message.comment.replace(/\{\{.*?\}\}/g, '')
// Search for exposed UUIDs
const regexp = /[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}/ig
const matches = Array.from(sanitizedComment.matchAll(regexp))
expect(matches.length, 'Exposed UUIDs').to.equal(0, 'Exposed UUIDs found')
}Example from Your AI Product Needs Evals
หรืออย่างการทำ text-to-sql เราก็อาจจะทดสอบหลายมุมมองฮะ เช่น
- Valid Query - SQL ที่ Generate ออกมาสามารถรันได้ไหม ถูก Syntax รึเปล่า
- Table/Column Check - ชื่อ Table/Column ที่ Generate ออกมาถูกไหม
- Execution Accuracy - เอา Generated SQL ไปรัน แล้วได้คำตอบตามที่ต้องการรึเปล่า
 Phasathorn Suwansri
Phasathorn Suwansri
Code-based Grading นั้นง่ายที่สุดเลยครับ เพื่อนๆ สามารถเขียนการทดสอบได้มากมาย เพราะมันแทบจะไม่เสียค่าใช้จ่าย ต่างจากแบบ Human-based grading และ LLM-based grading ที่อาจมีค่าใช้จ่ายเพิ่มเติมทุกครั้งที่รัน
2. Human-based Grading
ในบางสถานการณ์ การใช้ Code-based grading อย่างเดียวอาจจะไม่พอ การเอาผลลัพธ์ที่ได้ ให้คนช่วยตัดสินใจก็อาจจะง่ายกว่า และแม่นยำกว่าครับ แต่ว่าก็ต้องแลกมากับเวลา และอาจจะไม่ scale เท่าไหร่ครับ (เวลาข้อมูลเยอะๆ ก็ดูกันตาแฉะเลย 😆)
วิธีนี้คือการที่เราให้ Human มานั่งดูข้อมูลครับ ไม่ว่าจะเป็นดูจาก Google Sheet/Excels ของ Input/Output ว่าถูกต้องพอใจไหม
เครื่องมือบางตัว ก็อาจจะช่วยให้เรา เก็บข้อมูล และ ไล่ดูข้อมูลเพื่อทำความเข้าใจได้ง่าย ๆ อย่างเช่น LangSmith หรือ Langfuse
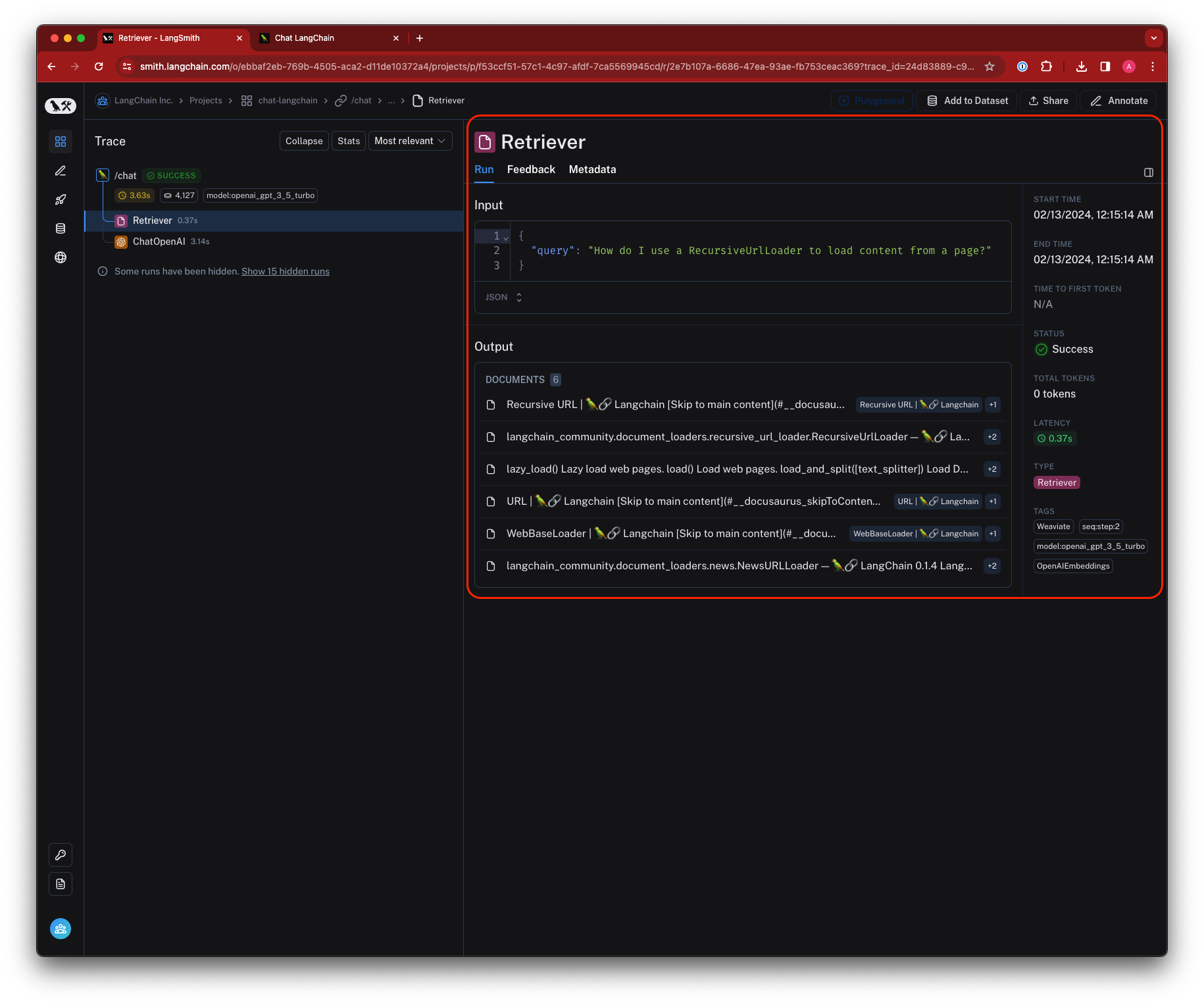
อีกตัวอย่างนึงคือ Anthropic Workbench ที่เราสามารถสร้าง prompt หลายๆ แบบ มาเทียบผลลัพธ์กันได้ฮะ
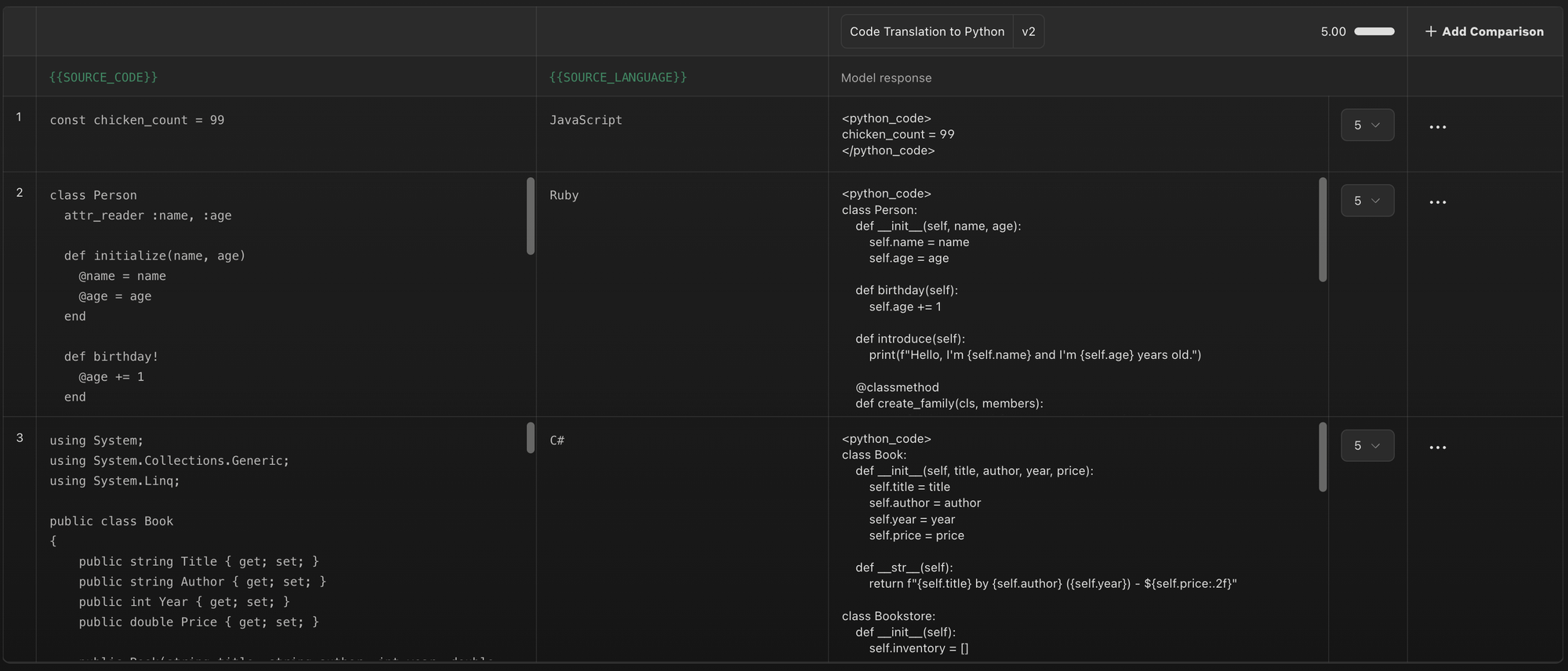
ส่วนตัวผมคิดว่าการสร้าง tool ขึ้นมาเอง อาจจะตอบโจทย์มากกว่า เพราะ Application ของเรา อาจจะมีมุมมองที่เราต้องการดูเป็นพิเศษ เช่นเราอยากจะ filter แบบไหน หรือดู format ที่เฉพาะบางอย่าง ที่ไม่สามารถใช้ tool ทั่วไปได้
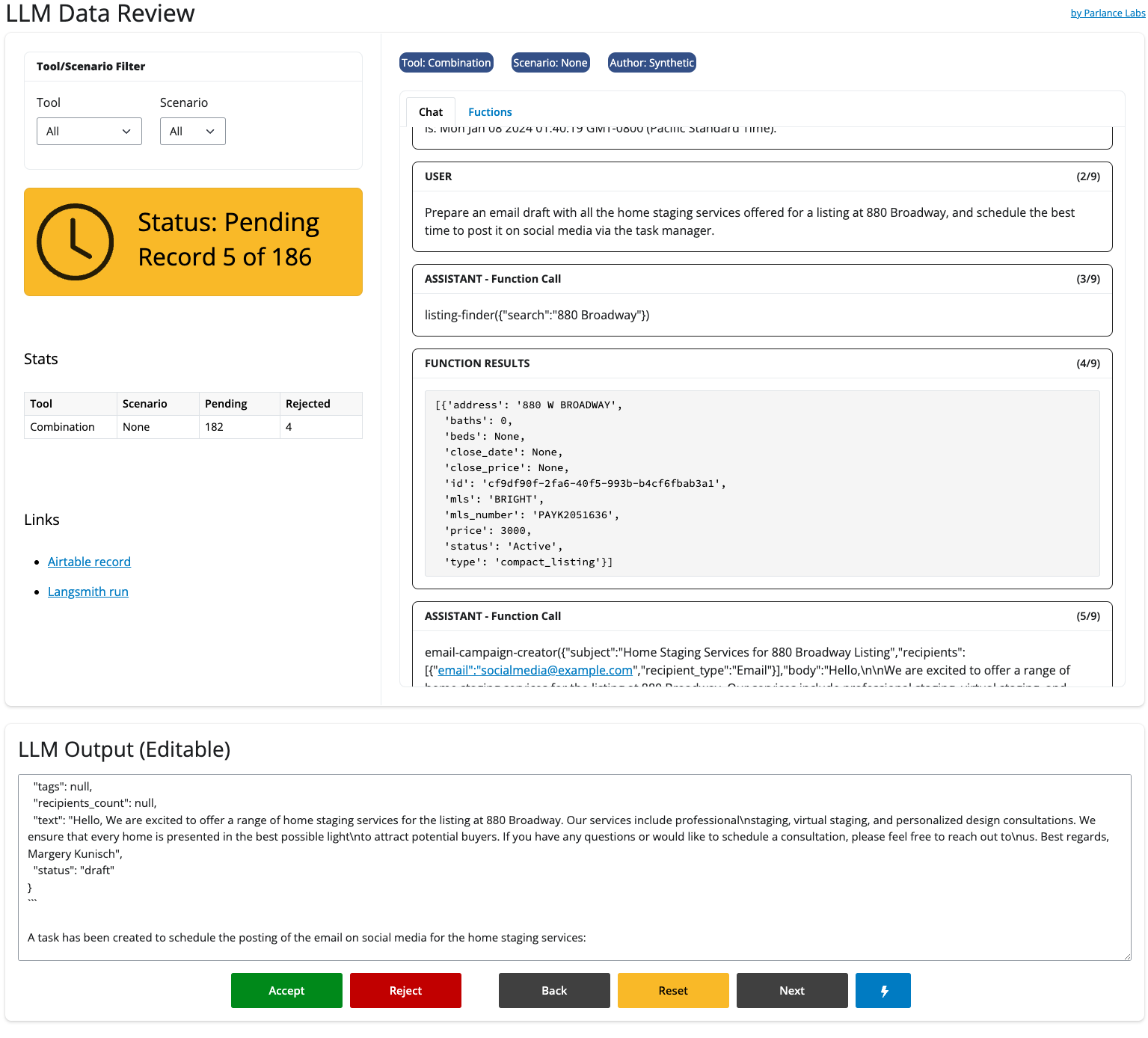
อย่างในบทความ Your AI Product Needs Evals เค้าก็ mention ไว้เช่นกัน ส่วนภาพด้านล่างเป็นตัวอย่างเครื่องมือที่เค้าทำขึ้นมาเพื่อใช้รีวิวการทำงานของ LLM Application ของเค้า
ArcFusion
ที่ ArcFusion เราก็สร้าง Evaluation Tool ที่ใช้กันภายในขึ้นมาฮะ เพื่อให้เราสามารถทำ Prompt Refactoring หรือ Prompt Tuning เพื่อให้ได้ผลลัพธ์ที่ดีที่สุด
Learn More3. LLM-based Grading (LLM-as-judge)
วิธีสุดท้าย LLM-as-judge คือ เราให้ LLM เป็นตัวช่วยในการทดสอบ โดยวิธีการ Prompt เราสามารถ ให้ 1) LLM ทำ Direct Scoring คือการขอคะแนนจาก LLM หรือ 2) Pairwise Comparison มีผลลัพธ์สองแบบให้ LLM เลือก ว่าแบบไหนดีกว่ากัน
Direct Scoring
Direct Scoring หรือบางคนอาจจะเรียกว่า Likert Scale คือการเราถามให้ LLM ช่วยให้คะแนนครับ จาก 1-5 คะแนนควรจะเป็นเท่าไหร่
ตัวอย่างด้านล่าง คือ เราให้ LLM ให้คะแนนว่า Summary ของ Article นี้ ดีมากแค่ไหน 1 คือแย่สุด และ 5 คือดีสุด ๆ
Evaluate the quality of summaries written for a news article. Rate each summary on four dimensions: {Dimension_1}, {Dimension_2}, {Dimension_3}, and {Dimension_4}. You should rate on a scale from 1 (worst) to 5 (best).
Article: {Article}
Summary: {Summary}Binary Factuality (Direct Scoring แบบ 0 หรือ 1)
วิธีนี้ คล้ายๆ กับการให้คะแนนครับ แต่ว่าให้ตอบแค่ ใช้ หรือไม่ อย่างตัวอย่างข้างล่าง เราถาม LLM ว่า ประโยคต่อไปนี้มีเนื้อหาที่ support จาก บทความนี้ไหม
Practitioner แนะนำวิธีนี้ มากกว่าให้ตอบเป็นตัวเลข 0-5 เพราะแต่ละคนอาจจะมี Scale ที่ต่างกัน ส่วนในเคสนี้ แน่นอนว่าแต่ละคนอาจจะตัดสินใจต่างกัน สิ่งที่เราควรจะขอเพิ่มจาก LLM นอกเหนือจาก Score แล้ว คือ คำอธิบาย (Model Critique) ว่าทำไมถึงตอบ "Yes" ทำไมถึงตอบ "No"
Is the sentence supported by the article? Answer "Yes" or "No".
Article: {Article}
Sentence: {Sentence}Pairwise Comparison
วิธีนี้คือการเทียบกันระหว่างสองตัวเลือก เราอาจจะเลือกใช้วิธีนี้ ถ้า ตัวอย่างมันแยกยาก เช่น Tone ของข้อความ, writing style แบบไหนดีกว่า
Given a new article, which summary is better? Answer "Summary 0" or "Summary 1". You do not need to explain the reason.
Article: {Article}
Summary 0: {Summary_0}
Summary 1: {Summary_1}ตรงนี้ถ้าใครไม่อยาก Implement เอง ลองใช้ Promptfoo ดูได้นะครับ
Promptfoo เป็น Tool สำหรับใช้ทดสอบ LLM เขียนด้วย Javascript

Who validates the Validators - Human Alignment
ถ้าเราเขียน Prompt ให้ LLM Validate ผลลัพธ์ แล้วเราจะรู้ได้ยังไงว่า LLM มัน Validate ถูกต้อง?
คำตอบก็คือ เราก็ต้องทดสอบตัว Validator ด้วยฮะ โดยให้ Domain Expert มาช่วย Validate
Practitioner หลายคน รวมถึง Research Paper มักจะ Mention ว่า ผลลัพธ์ของ LLM บางทีมันไม่ Align กับสิ่งที่เราต้องการ
อย่างบทความ Your AI Product Needs Evals - Hamel Husain เค้าให้ทำการ Optimize Process นี้โดยที่ให้ LLM ตอบทั้งคำตอบ และ critique (คำวิจารณ์) เสร็จแล้วเค้าก็ใส่ไปใน Google sheet แล้วให้ Human ตอบมาคู่กัน
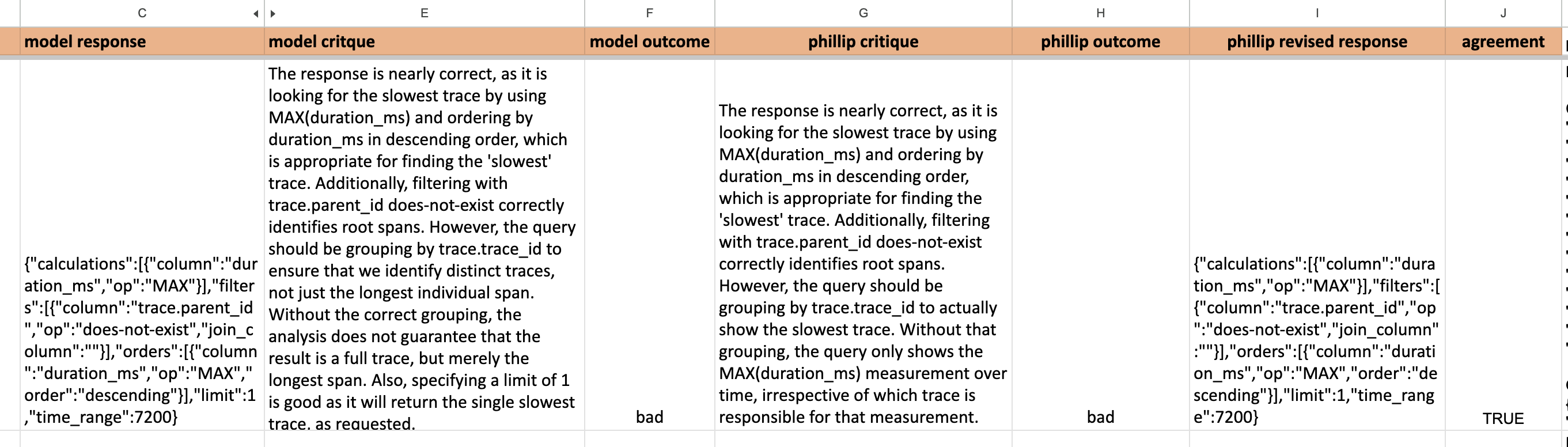
หลังจากนั้นก็เอามาแก้ Prompt ให้ผลลัพธ์ของ LLM กับ Human มันเป็นไปในทางเดียวกัน
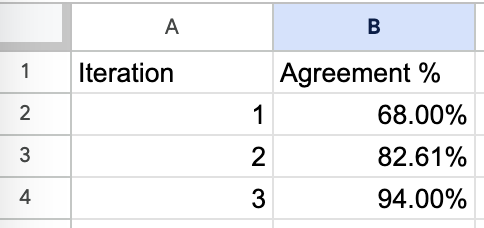
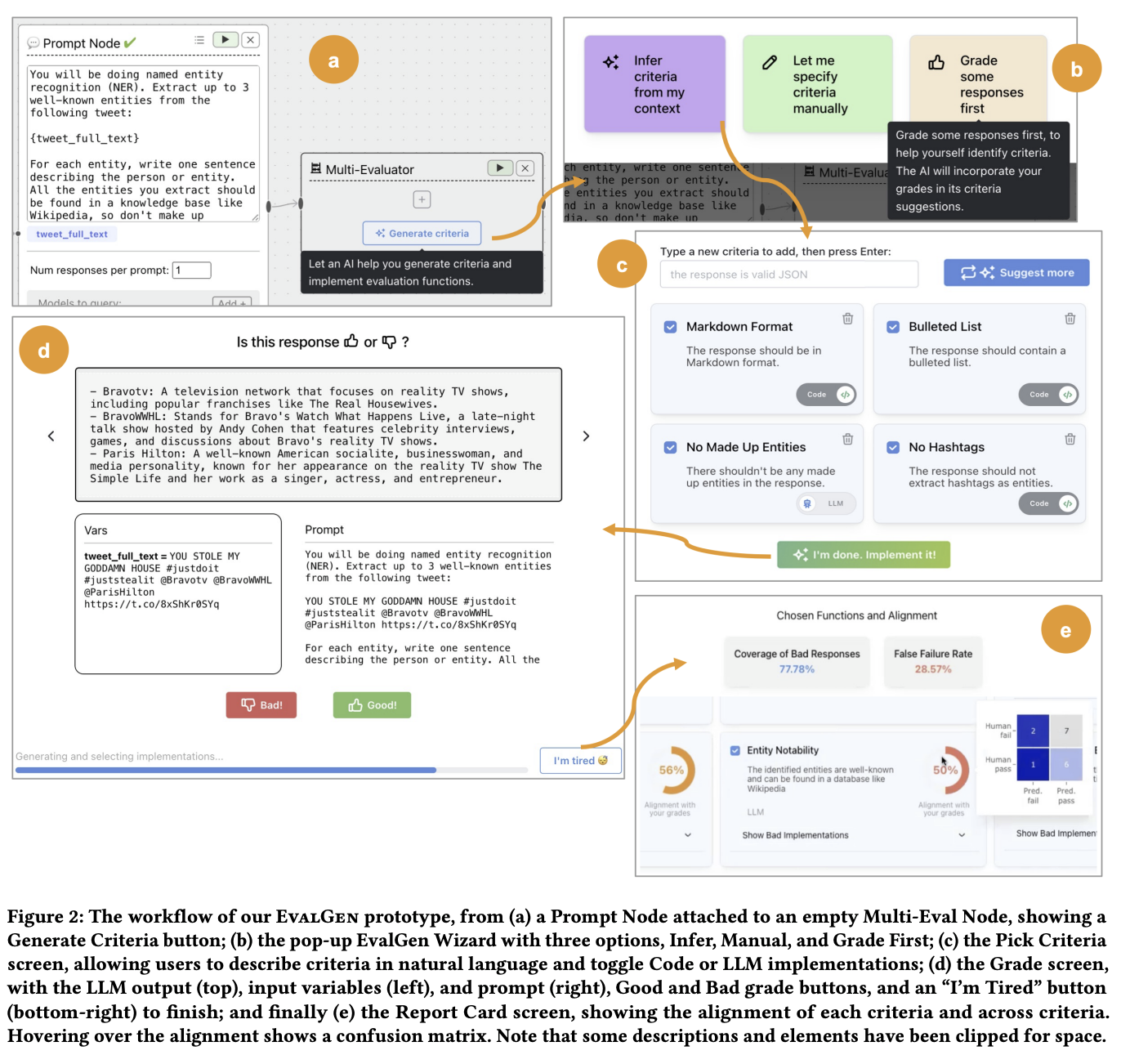
หรืออีกตัวอย่างจาก Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences เค้า Propose EvalGen ซึ่งเป็นเครื่องมือที่ช่วยให้ Human Refine Criteria สำหรับ Validate ได้ดีขึ้น
จากภาพข้างล่าง แทนที่เราจะให้ LLM Evaluator แบบ Fix Prompt มาแล้ว รันไปเลยทีเดียว EvalGen ให้ LLM สร้าง Criterias มาก่อน แล้ว Human ดูว่ามี Criteria ไหนที่ควรใช้บ้าง แล้วเค้าเอา Criteria นั้นไปรัน
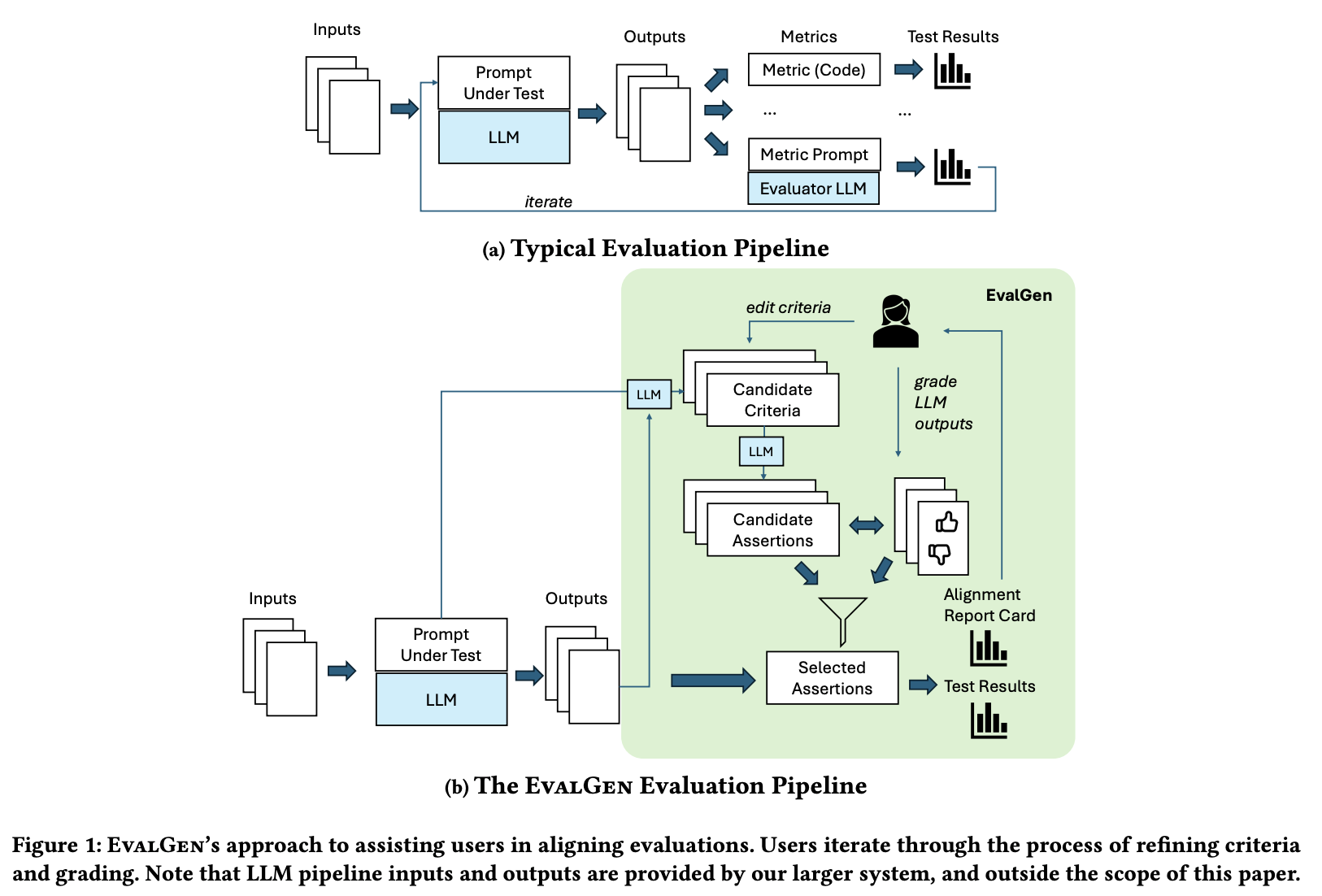
ภาพข้างล่างเป็นตัวอย่าง Tool EvalGen ครับ
ถ้าใครสนใจเพิ่มเติมเรื่อง Human Alignment ลองดู Prototype Project ของ Eugene ได้นะครับ เผื่อเป็นไอเดียในการทำ Alignment เพิ่มเติม
Interesting Reads
บทความข้างล่างนี้อยากให้ตามไปอ่านดูครับ อธิบายละเอียดยิบ ว่า LLM-as-Judge ที่ดี ควรทำยังไง Step-by-step
How to get started
- เสริมความแกร่งด้วย code-based grading
- หา Domain Expert มาเตรียม test set
- Human-based Grading (aka. Eyeballing)
- ทำ LLM-as-judge แล้วก็ Tune Prompt ให้สอดคล้องกับ Human
- ติด Logging/Tracing tools
จากที่ Explore หลาย ๆ ที่ รวมถึงประสบการณ์ส่วนตัว
1.เสริมความแกร่งด้วย code-based grading
เริ่มจากเขียน Code- base grading ก่อนเลยฮะ เพราะว่าง่ายที่สุด และเนื่องจากว่า น่าจะเป็น development process ของ software development อยู่แล้ว ก็เริ่มได้เลยครับ โดยที่ test set ชุดแรก ๆ อาจจะไม่ต้องละเอียดเก็บทุก function ก็ได้ครับ อาจจะมีแค่เพื่อให้อุ่นใจไว้หน่อย 🫰
2.หา Domain Expert มาเตรียม test set
ผมเห็นด้วยกับ Blog ของ Hamel ว่าเราควรชวน Domain Expert มาช่วยเตรียม test set นอกจากจะได้มุมมองที่น่าสนใจแล้ว ยังเห็นรายละเอียดว่า Application ของเราจะถูกใช้ยังไงอีกด้วย
แต่ถ้าไม่มี Domain Expert เราสามารถคิด test set เพิ่มขึ้นมาเองได้ฮะ หรือถ้าเรารู้รูปแบบของ input query เราอาจจะสร้าง Synthetic dataset จาก Grammar ที่เราตั้งขึ้นมาก็ได้
metrics = ["impression", "clicks", "ctr"]
number = ["two", "three"]
date_unit = ["days", "months", "weeks"]
template = "What is the {metrics} over the last {number} {date_unit}"หรือสร้าง Synthetic Dataset โดยใช้ LLM
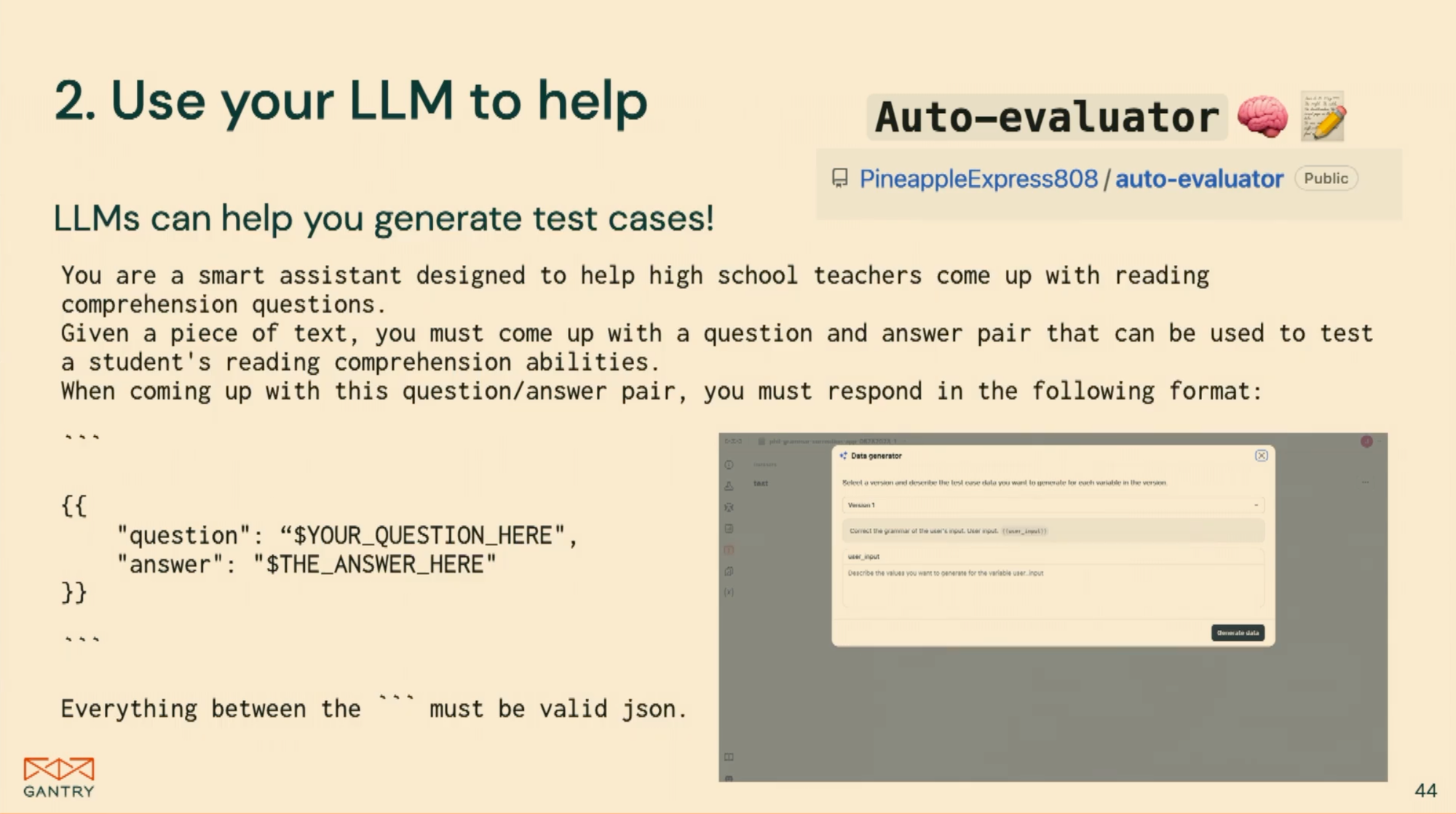
หรือตัวอย่างใน Blog ของ Hamel

3.Human-based Grading (aka. Eyeballing)
ก่อนจะไปทำ LLM-as-Judge ให้คนมาช่วย Evaluate ก่อนก็ได้ครับ แต่พอเราทำไปเรื่อยๆ พอเทสเยอะๆ มันจะ scale ยากแล้ว ต้องมาดูผลลัพธ์เทสบ่อยๆ ก็ตาฉ่ำ พอดี พอถึงจุดนั้นเราค่อยทำให้มันดีขึ้นด้วย LLM-as-Judge
4.ทำ LLM-as-judge แล้วก็ Tune Prompt ให้สอดคล้องกับ Human
อย่างที่ Mention ไว้ด้านบนฮะว่า LLM บางที Evaluate ไม่เหมือนกับที่เราต้องการ เราก็ต้องให้ Human มาช่วย Evaluate คู่กันไปฮะ แล้วเราก็ Tune Prompt เพื่อให้ผลลัพธ์ของ LLM ตรงกันกับสิ่งที่เราต้องการ (ตัวอย่างโดยละเอียดจาก Blog ของ Hamel)
4.ติด Logging/Tracing tools
อย่าลืมติด Logging/Tracing แล้วเอาข้อมูลการใช้งานของลูกค้ามาเติมเทสเข้าไปเรื่อย ๆ ครับ อย่าง LangSmith หรือยังไม่มี Idea ว่าจะทำ evaluation ยังไง ลองดูตัวอย่างใน Document ของ LangSmith Evaluation ได้นะครับ
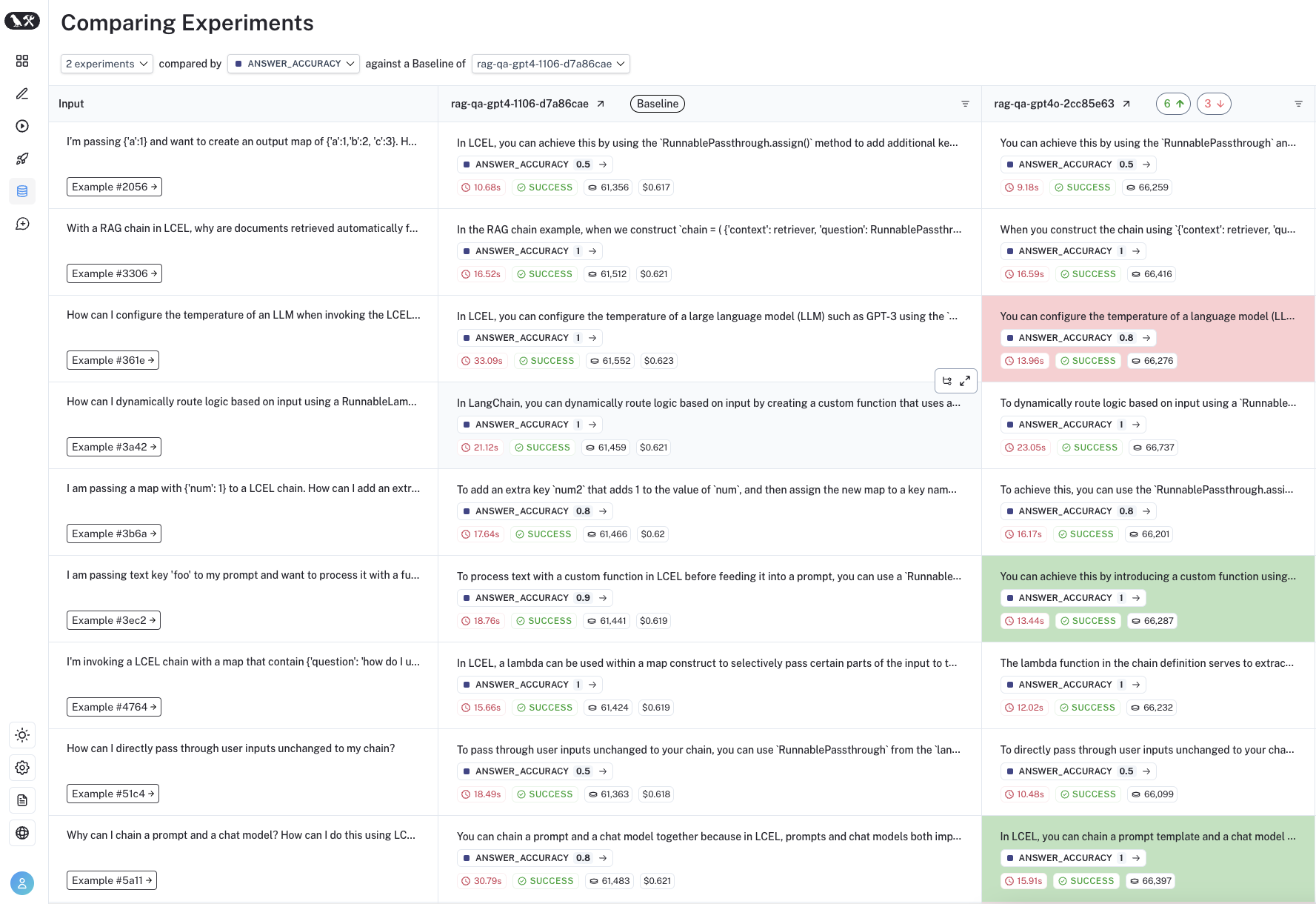
หรือ Tool อื่น ๆ เช่น LangFuse เราก็สามารถเอา Query จริงๆ ที่ลูกค้าใช้งานแล้ว ระบบ Log ไว้ มาสร้างเป็น Dataset เพื่อไปรัน Evaluation เพิ่มเติมได้
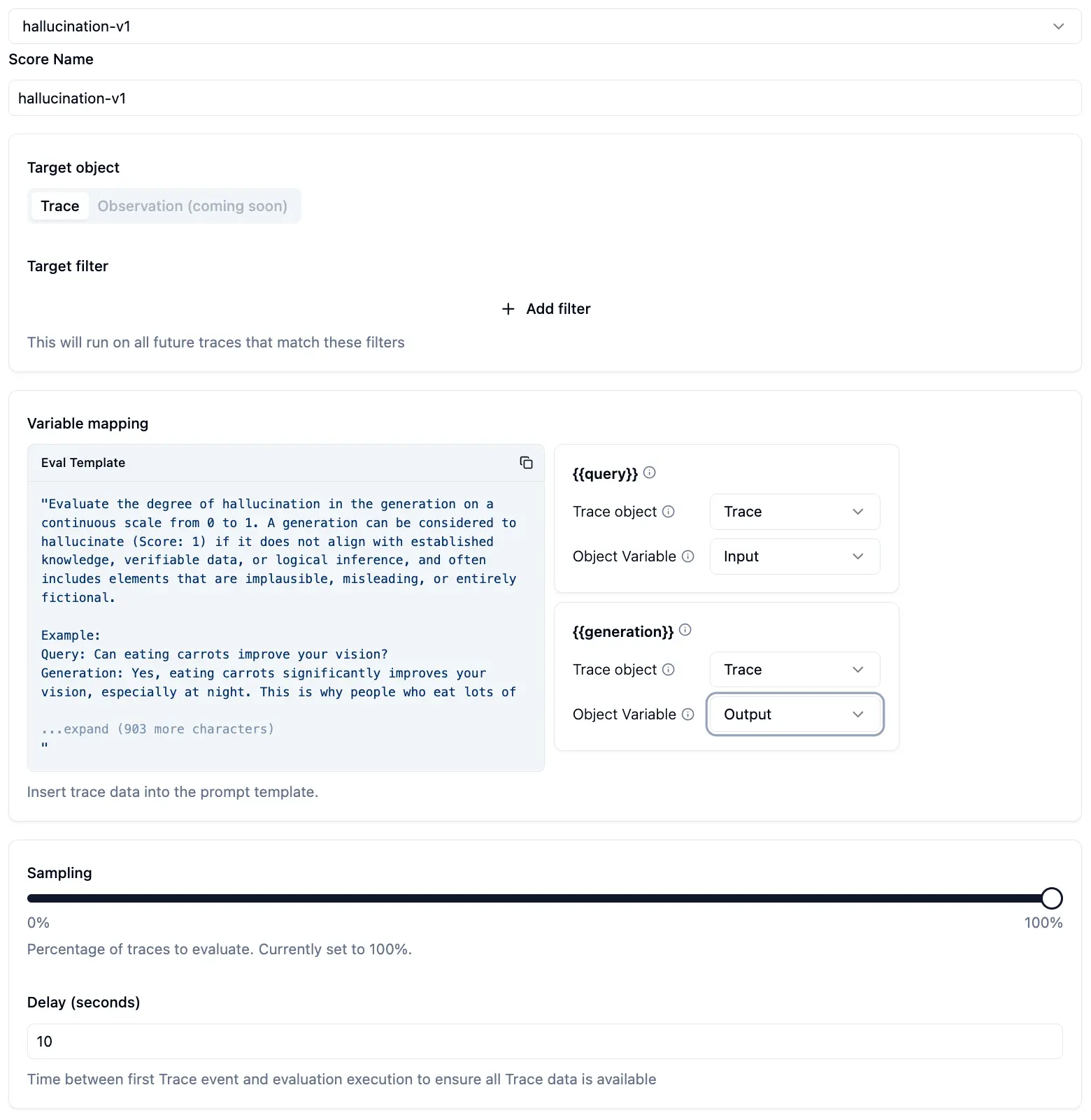 Phasathorn Suwansri
Phasathorn Suwansri
Other Interesting Ideas
Idea และ Technique อื่นๆ จาก paper ที่ Eugene Review ไว้ก็น่าสนใจฮะ
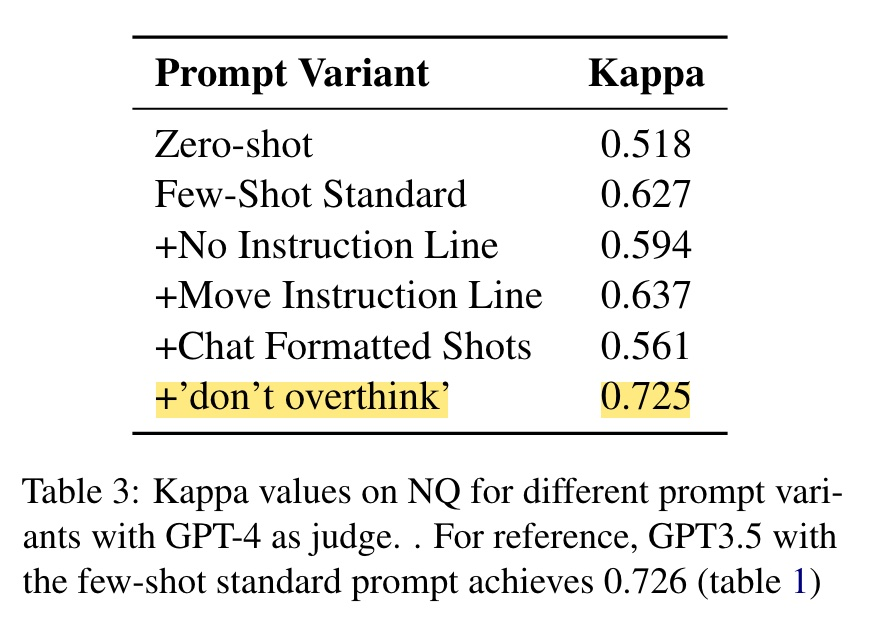
- ใครใช้ Model ตัวแพงๆ เป็น LLM-as-Judge แล้วได้ผลไม่ดี ลองเติมคำว่า "+ don't overthink" เข้าไปดูฮะ
- หรืออย่างไอเดียของ PoLL ที่ใช้ LLM ตัวเล็กหลาย ๆ ตัว (command-r, gpt-3.5-turbo, haiku) มาช่วย Judge ก็ได้ผลดีกว่าใช้ LLM ตัวใหญ่ตัวเดียว
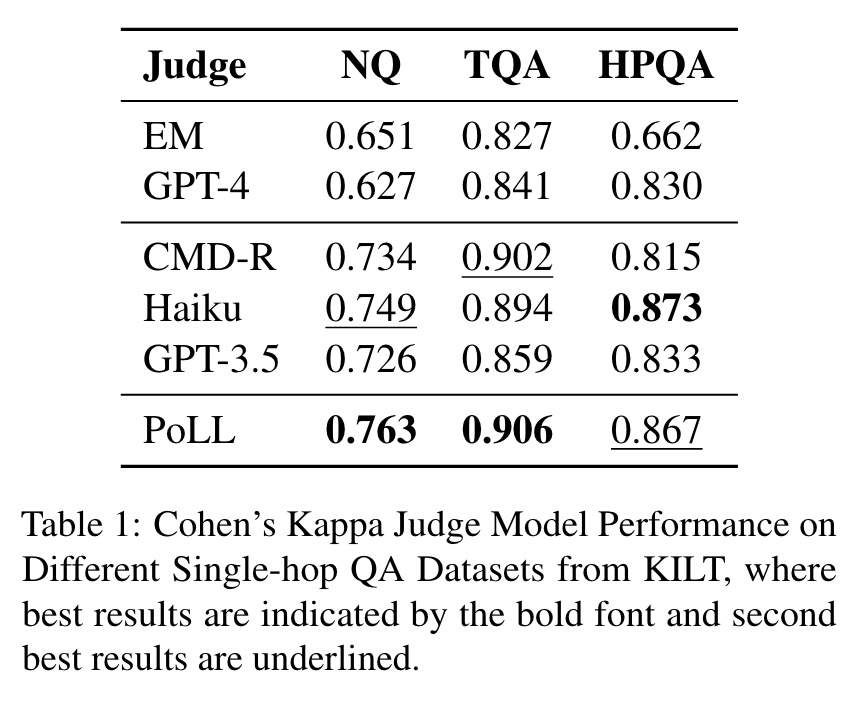
Looking Ahead
อ่านมาจนจบถึงตรงนี้แล้ว หวังว่าทุกคนคงเห็นภาพว่าเราจะประเมิน Prompt หรือ LLM Application ของเราได้อย่างไร ทั้งแบบ Code-based, Human-based, หรือ LLM-based และเราจะนำไปใช้ใน Application ของเราอย่างไร เพื่อให้มั่นใจว่าจะไม่มีอะไรพัง และเพื่อให้ผู้ใช้ของเราเชื่อมั่นในผลิตภัณฑ์ของเรา 😄
ในอนาคต อาจจะมีรูปแบบการ Evaluate ใหม่ๆ ออกมา เครื่องมือหรือเทคนิคอื่น ๆ ยังไงก็รอติดตามกันได้นะคร้าบ
หากใครมีเนื้อหาเพิ่มเติมหรือวิธีที่ลองแล้วได้ผล ทักมาคุยกันได้นะครับ ขอบคุณครับ 👋
References
- Engineering Practices for LLM Application Development - David Tan, Jessie Wang
- Your AI Product Needs Evals - Hamel Husain
- Anthropic Prompt Evaluation
- Evaluating LLM-based Applications
- LangSmith Evaluation
A big issue I see with AI systems is that people aren't spending enough time evaluating their evaluation pipeline.
— Chip Huyen (@chipro) May 10, 2024
1. Most teams use more than one metrics (3-7 metrics in general) to evaluate their applications, which is a good practice. However, very few are measuring the…