Text-To-SQL ด้วย LLM


Text-to-SQL ด้วย LLM มันเวิร์คไหมนะ? 🤔
เดี๋ยวนี้ Large Language Model (LLM) กำลังฮ็อตฮิตสุด ๆ เลยนะครับ หลายคนก็เลยอยากจะเอามาใช้งานกับข้อมูลตัวเองบ้าง โดยเฉพาะอย่างยิ่งการคุยกับฐานข้อมูลด้วยภาษาธรรมดา แล้วให้มันสร้าง SQL Query มาให้เราเลย อย่างเจ๋ง! 🚀
จริง ๆ แล้ว มันก็ไม่ยากเลย เพียงแค่ส่ง prompt ไปถามก็จะได้ SQL กลับมาแล้ว แต่ปัญหาคือ LLM มันไม่รู้จัก schema ในฐานข้อมูลเรา เลยทำให้ SQL ที่ได้ออกมาแบบกว้าง ๆ ไม่ specific กับข้อมูลเรา 😅
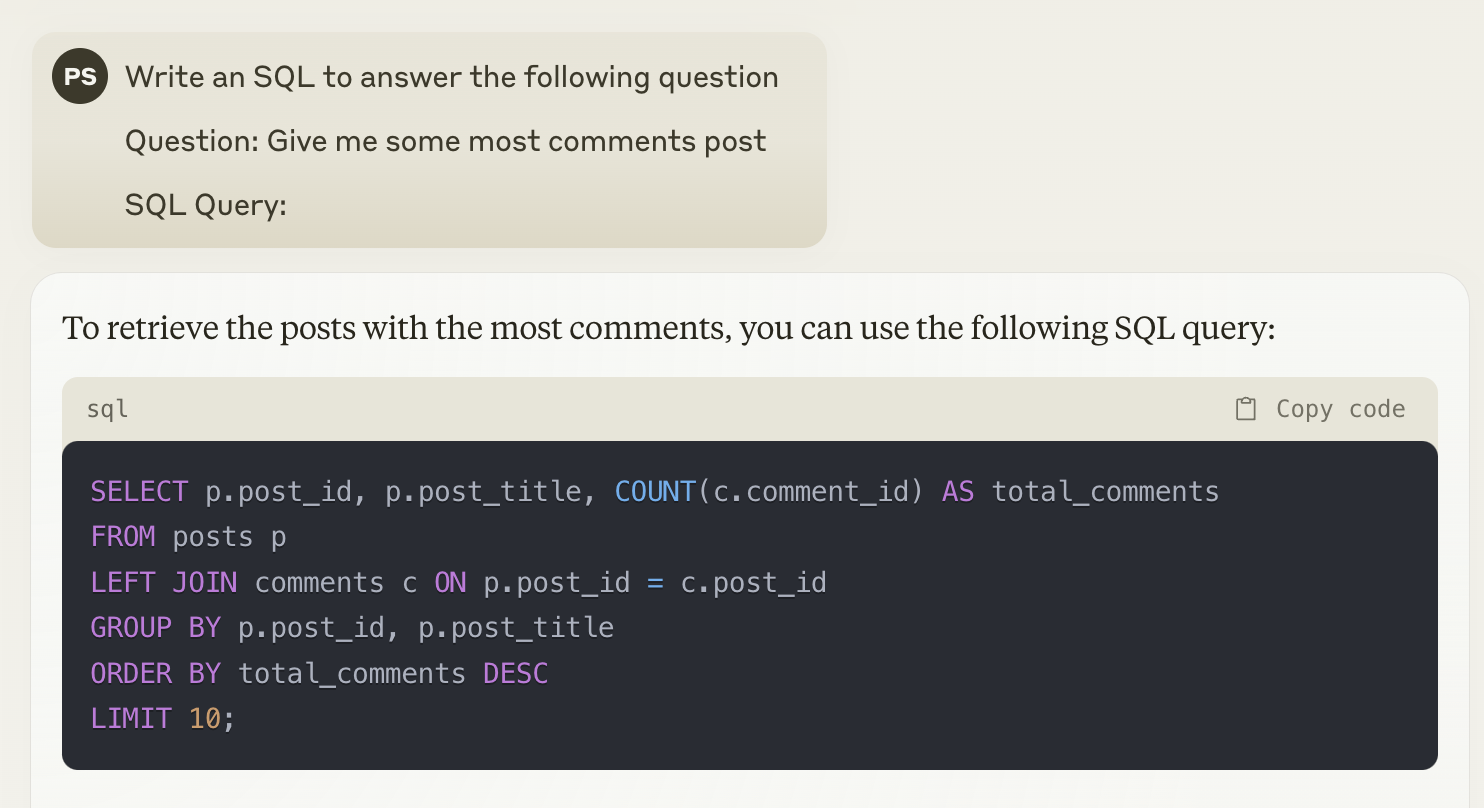
แต่ไม่ต้องห่วงครับ เพราะตอนนี้มีเครื่องมือดี ๆ อย่าง LangChain ช่วยเราได้ มันจะเอา schema และ sample data ส่งไปให้ LLM ด้วย จะได้รู้ว่าต้องสร้าง SQL ให้ตรงกับฐานข้อมูลเรา
การส่ง sample data อาจจะมีปัญหาเรื่องความเป็นส่วนตัว
ใครอยากจะลองเอาไปต่อ SQL database ของตัวเอง เพื่อทำ Chat with data ง่าย ๆ ก็จิ้มไปตาม Tutorial เลยครับ


ถ้าใครลองใช้งานจริงก็จะเจอปัญหาอยู่บ้าง เช่น บางทีชื่อ column มันกำกวม หรือบางทีค่าใน value มี format พิเศษ ทำให้ LLM เลือกผิดได้ แบบนี้ต้องมาดูวิธี improve ต่อแล้วล่ะ 💪
ในบทความนี้ ผมพาจะไปดู Resources ที่น่าสนใจ สำหรับการทำ Text-To-SQL กันครับ
- Challenges of Text-to-SQL
- Improving Text-to-SQL
Challenges of Text-to-SQL
Text-to-SQL มันไม่ใช่เรื่องง่ายเลยจริง ๆ นะเนี่ย 😅 ผมไปอ่านบทความมาเรื่อง A survey on deep learning approaches for text-to-SQL เค้าก็สรุปความท้าทายหลัก ๆ มา 2 ด้านครับ
Natural Language (NL) challenge
เริ่มจากปัญหาภาษาธรรมดาของเรากันก่อนเลย ด้วยความกำกวมของภาษามนุษย์ เดี๋ยวคำนึงมีหลายความหมาย เช่น "Paris" อาจจะเป็นชื่อเมือง หรือไม่ก็ชื่อคนอะไรงี้ 🤨
บางทีรูปประโยคเดียวกันยังแปลได้หลายแบบเลย อย่าง "Find all German movie directors" อาจจะหมายถึง "director ที่กำกับหนังเยอรมัน" หรือ "director ที่เป็นคนเยอรมันแล้วกำกับหนัง" ก็ได้
แล้วพวกคำขยายอย่าง top, best ก็ดูจะไม่ค่อยชัดเจน top movie มันวัดจากอะไรกันนะ นี่ถ้าเอาไปถาม LLM ป่านนี้คงจะสับสนกันพอดี
SQL Challenge
ต่อมาคือความท้าทายในการสร้าง SQL ปัญหาหลัก ๆ เลยก็มีเรื่องชื่อ column หรือ value ในโจทย์ที่อาจจะไม่ตรงกับใน table จริง ๆ เช่น actress อาจจะหมายถึง Actor.name ในตาราง
ชื่อ schema เองก็อาจมีหลายความหมาย model อาจหมายถึง car.model หรือ engine.model
ที่แย่กว่านั้นคือคำถามที่ต้อง join หลาย ๆ table LLM ต้องไปเดาเอาว่าควรจะ join ตารางไหนยังไงถึงจะถูก เช่น Find the director of movie "A Beautiful Mind" แบบนี้ ก็อาจจะต้อง Join ระหว่าง Movie กับ Actor table
ใครอยากรู้รายละเอียดลึก ๆ ไปตาม paper เต็ม ๆ กันเลยครับ รับรองว่าได้ความรู้กลับมาแน่นอน อย่างน้อยเราก็รู้แล้วครับว่า ทำไม text-to-SQL ถึงยากจัง
Improving Text-to-SQL
มาถึงตรงนี้ หลายคนคงสงสัยแล้วสินะว่า เอ๊ะ แล้วเราจะทำยังไงให้ Text-to-SQL ของเราเจ๋งขึ้นได้อีกล่ะ? 🤔 เดี๋ยวผมจะมาเหลา (เล่า!) ให้ฟังครับว่ามีวิธีไหนที่น่าสนใจบ้าง
- Improve through prompting
- Improve through RAG
- Improve through Finetuning
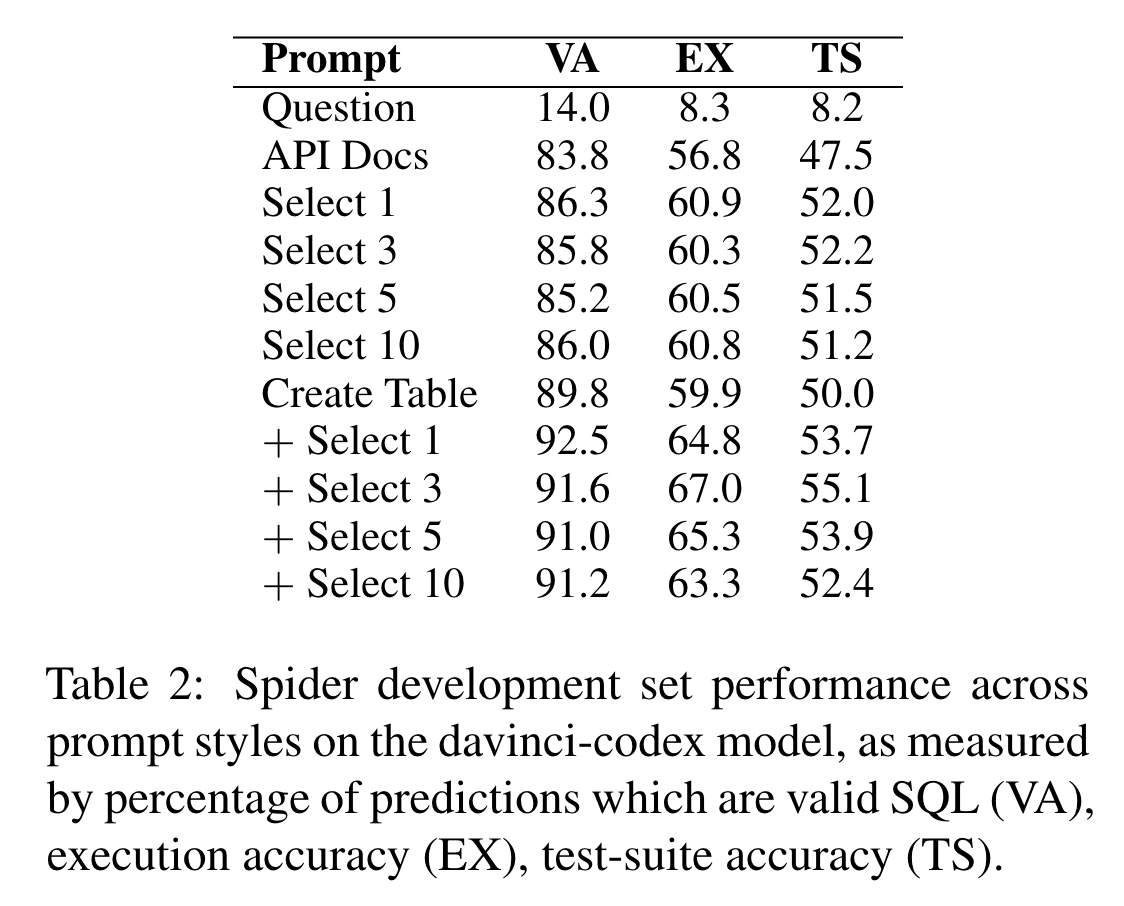
Improve through prompting
ขอเริ่มที่วิธีแรกเลยนะ นั่นก็คือการปรับ prompt นั่นเอง มันดูง่ายแต่ได้ผลชะมัด แค่ใส่คำอธิบายลงไปใน prompt เช่น schema หรือ sample data ก็ช่วยให้ LLM เข้าใจบริบทได้ดีขึ้นแล้ว ถ้าใครเคยเห็นโค้ดของ LangChain คงเคยเห็นที่เขาใส่ table_info ลงไปใน prompt แบบนี้แหละ แต่บอกตรงๆ ว่ามันก็ยังไม่สมบูรณ์แบบร้อยเปอร์เซ็นต์หรอกนะครับ บางทีก็ยังมีข้อผิดพลาดอยู่
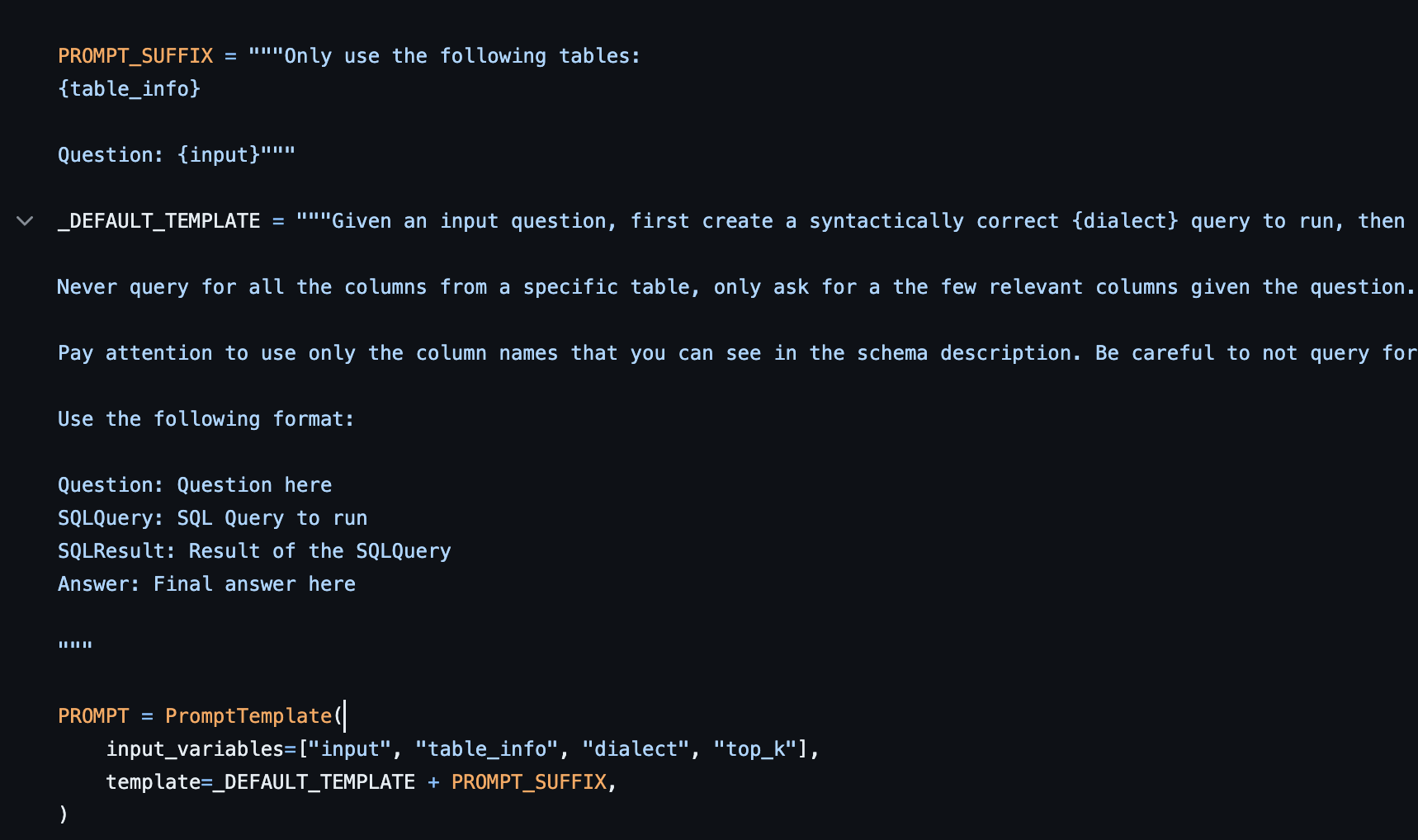
Prompt with table info/schema
- ใส่ Table Schema (DDL) เข้าไปใน Prompt เหมือนตัวอย่างที่ LangChain นำมาใช้เลยครับ จัดไปเต็มๆ เลยจะได้รู้ชื่อ table, column, type ทั้งหมด

Prompt with contextual
เอาล่ะ ถ้าอยากปรับ prompt ให้เทพขึ้นไปอีก ก็มีวิธีเช่น
- ใส่ context หรือคำอธิบายลงไปด้วย จะได้รู้ลึกถึงความหมายของ table และ column
- ใส่ sample data เช่น data 3 แถวแรก หรือ distinct value ใน column นั้นๆ
- ใส่เอกสารอธิบาย เช่น table นี้คืออะไร column นี้แปลว่าอะไร format เป็นยังไง
- ใส่ตัวอย่าง SQL ที่เคยถามแล้วเป็น historical data ไปเลย จะได้เป็น few-shot learning

Prompt with Knowledge Graph
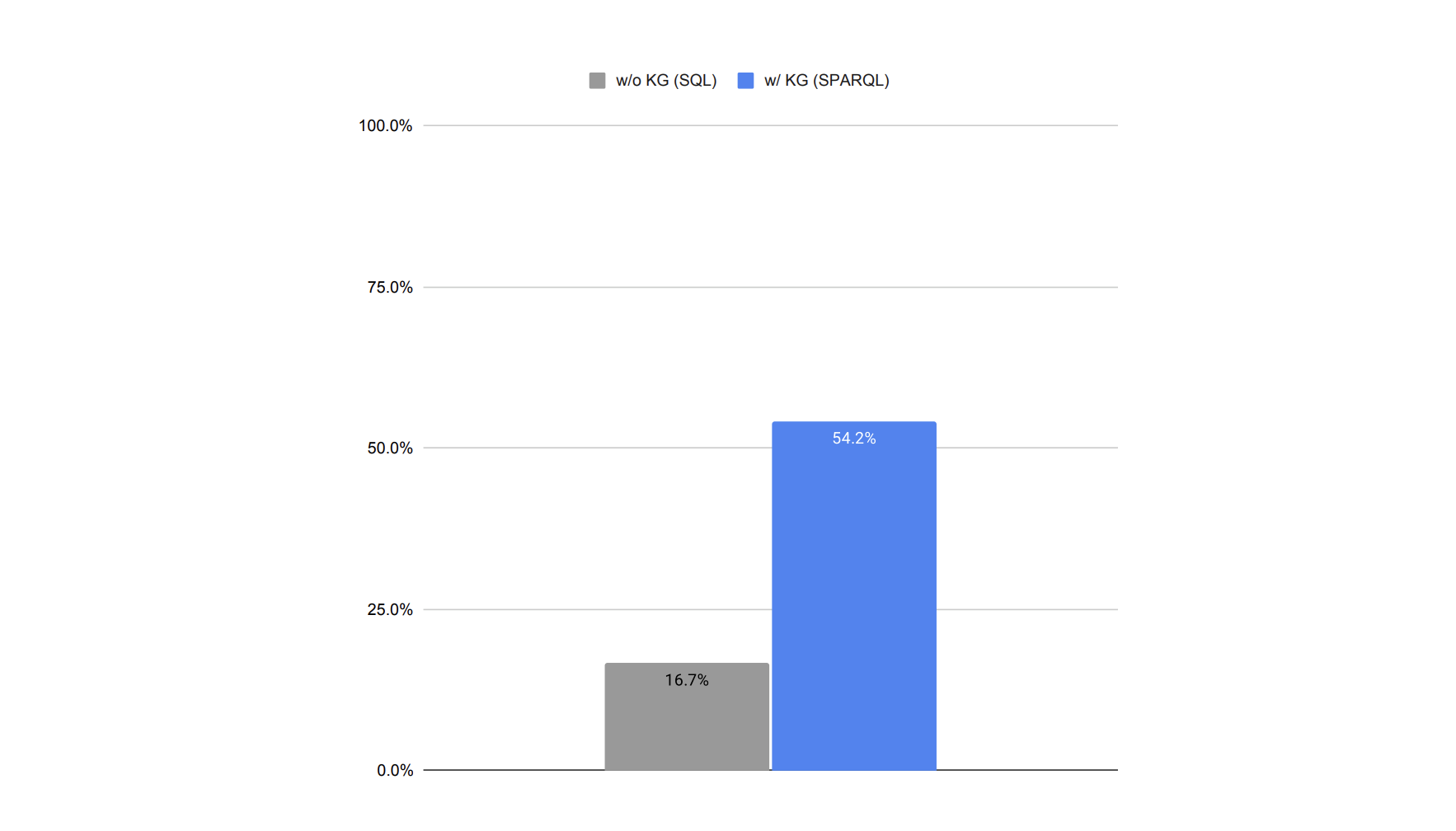
แต่เดี๋ยวก่อน! ใครบอกว่าต้องเล่นแต่ SQL จ๋า ทำไมไม่ลอง Knowledge Graph บ้างล่ะ? จากงานวิจัยเขาบอกว่า ถ้าเอา SQL มาทำเป็น SPARQL แล้วใช้กราฟแสดงความสัมพันธ์ของ table เนี่ย ผลลัพธ์ดีขึ้นเยอะเลยนะ 😮
Improve through RAG
แต่แน่นอน prompt ต้องเคียงคู่กับเทคนิคยอดฮิตอย่าง Retrieval Augmented Generation (RAG) เพราะในความเป็นจริงที่มี table เยอะ มี documentation หลายรูปแบบ มีวิธี query หลากหลาย prompt อย่างเดียวคงไม่พอแน่ๆ ใครอยากรู้ว่า RAG มันเวิร์คยังไง อ่านเพิ่มได้จากลิ้งค์ด้านล่างเลยครับ
 Phasathorn Suwansri
Phasathorn Suwansri
VannaAI
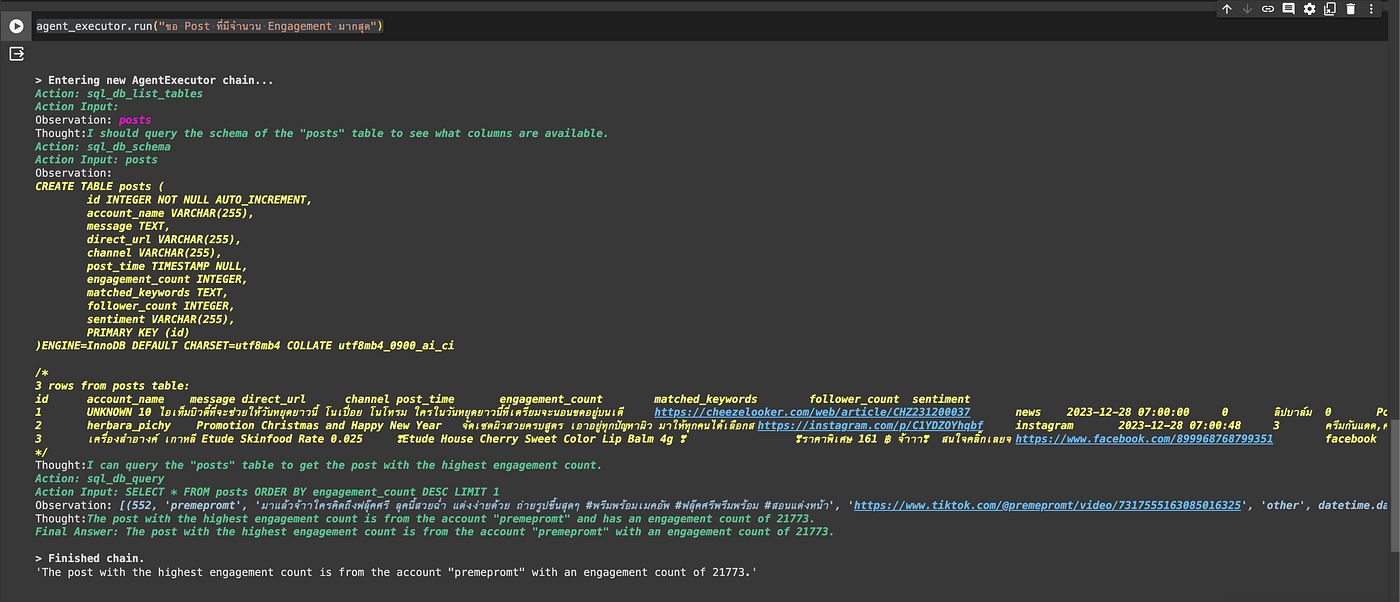
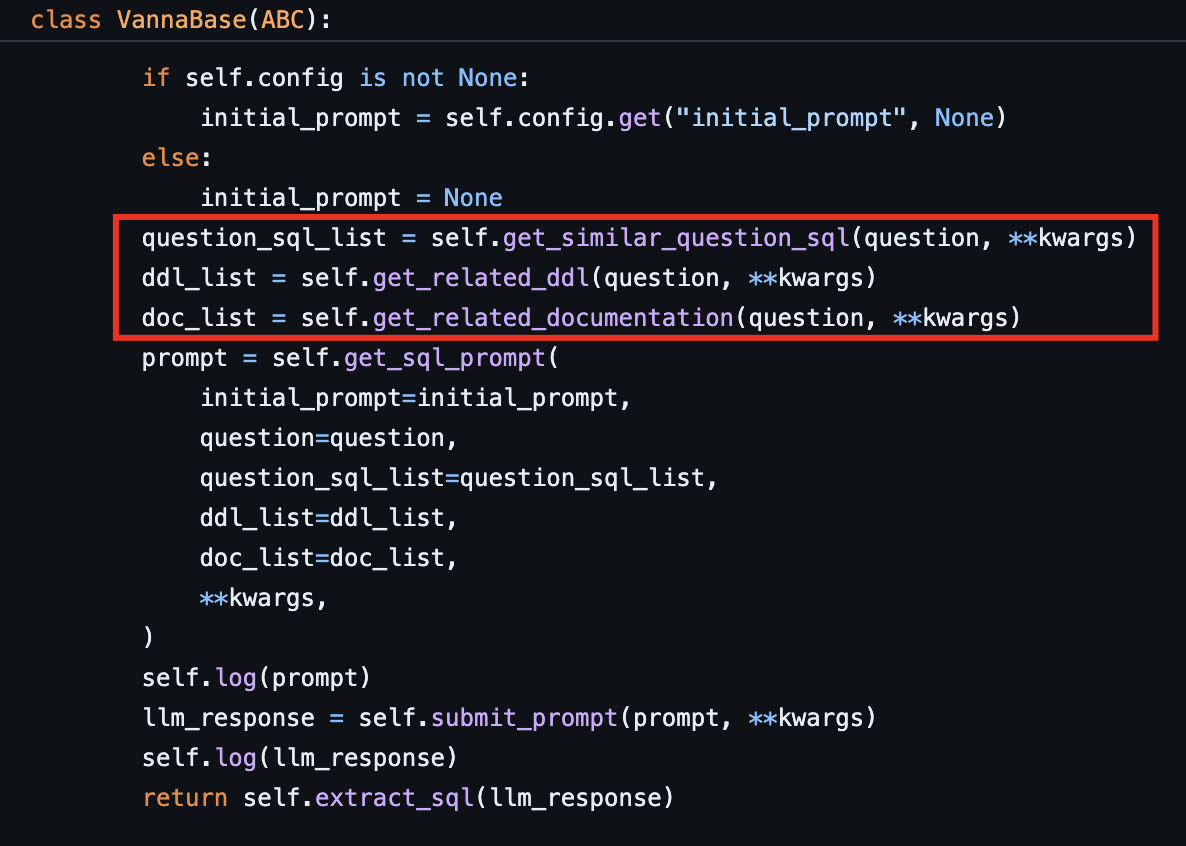
ใครที่ไม่อยากเขียนเอง ก็มีคนใจดีทำ open source อย่าง Vanna AI ไว้ให้แล้ว แค่โหลด doc กับ schema เข้าไป พอถามคำถามปุ๊บ มันก็จะไปหา context ที่เกี่ยวข้อง แล้วยิงให้ LLM สร้าง SQL ที่แม่นยำกลับมาให้เฉยเลย เขาทดสอบแล้วนะว่าช่วยเพิ่ม accuracy ได้เยอะมากแหละ
ตัว Vanna มีหลักการทำงาน คร่าว ๆ คือ เค้าทำ RAG แยก 3 ส่วนครับ
- สำหรับ Documentation เช่น เอาไว้ใส่เนื้อหาคำอธิบายของแต่ละ table ถ้าเรามีอยู่แล้วก็โหลดเข้าไปโล้ดเลยครับ
- สำหรับ DLL พวก Table Schema เช่น Table A มี 5 column แต่ละ column ชื่ออะไร คืออะไร เป็นข้อมูลประเภทไหน
- สำหรับ Question-SQL เช่น คู่คำถาม (post ที่คน comment เยอะที่สุด) ให้ใช้ SQL อะไร
ตัว vanna ยังมีฟีเจอร์ อื่นๆ ที่น่าสนใจอีกครับ เช่น question suggestions เอาไว้ช่วยคิดคำถาม ว่าถ้ามี SQL แบบนี้ ถามอะไรได้บ้าง หรือแม้กระทั่งให้ LLM เขียนโค้ดเรียกใช้ Plotly (library ในการสร้างกราฟ) เพื่อ Visualize ผลลัพธ์
 vanna-ai
vanna-aiAdditional methods
วิธีอื่นๆ ที่น่าสนใจก็มีอีกเพียบ เช่น
- Decomposition: แยกคำถามใหญ่ให้เป็นคำถามย่อยๆ
- Self-correction: ถ้า SQL ที่ออกมารันไม่ได้ ก็ให้ LLM ช่วย fix เอง
- Finetuning: เอา model มา finetune ใหม่ เห็นมี startup อย่าง defog.ai บอกว่าทำได้ดีกว่า GPT-4 เลยนะ ทำเป็นเล่น! 🤩
Decomposition
วิธีนี้ จะคล้ายๆ กับ ใน RAG ครับ โจทย์คือ เวลาคำถามมันซับซ้อน เราอาจจะต้องแยกคำถามใหญ่ ออกมาเป็นคำถามย่อย ๆ
Self Correction
Self Correction คือในเคสที่ถ้า SQL ที่ LLM Generate ออกมา แล้วมันรันไม่ผ่าน เราก็จะให้ LLM ทำการ Fix ให้
เราอาจจะ Implement ง่าย ๆ โดยการให้ข้อมูล LLM ประมาณนี้
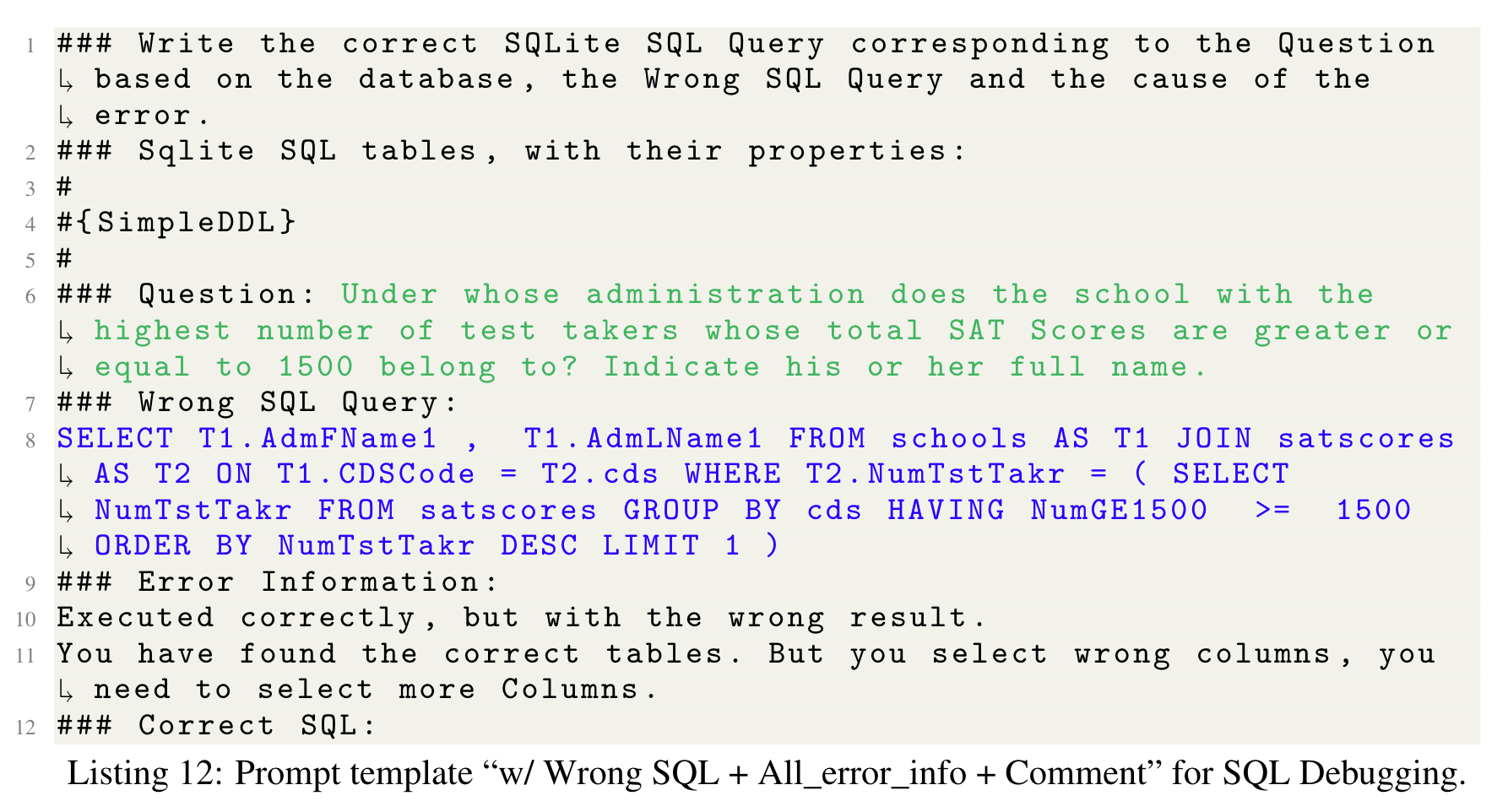
Improve through the finetuning
- มีคนเอา Model มา finetune แล้วก็ได้ผลลัพธ์ดีกว่า Model ปกติ อย่างเจ้านี้ครับ defog.ai เป็น Startup ที่เค้าก็ claimed ว่าได้ผลดีกว่า gpt4 อีกนะ
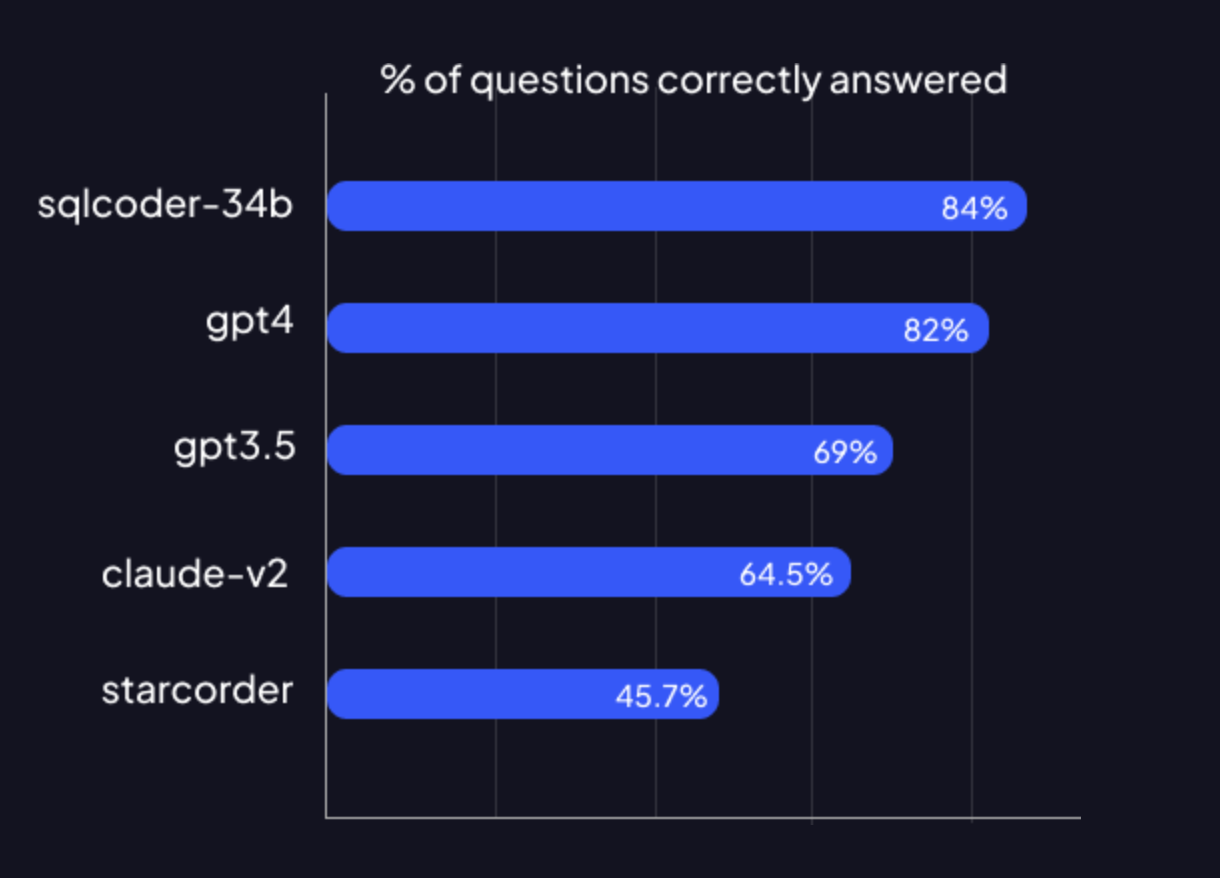

ใครที่ทำแล้ว ไม่รู้ว่าจะวัดผลยังไง มันดีขึ้นไหม ลองตามไปอ่านบทความนี้กันได้ครับ
Phasathorn Suwansri
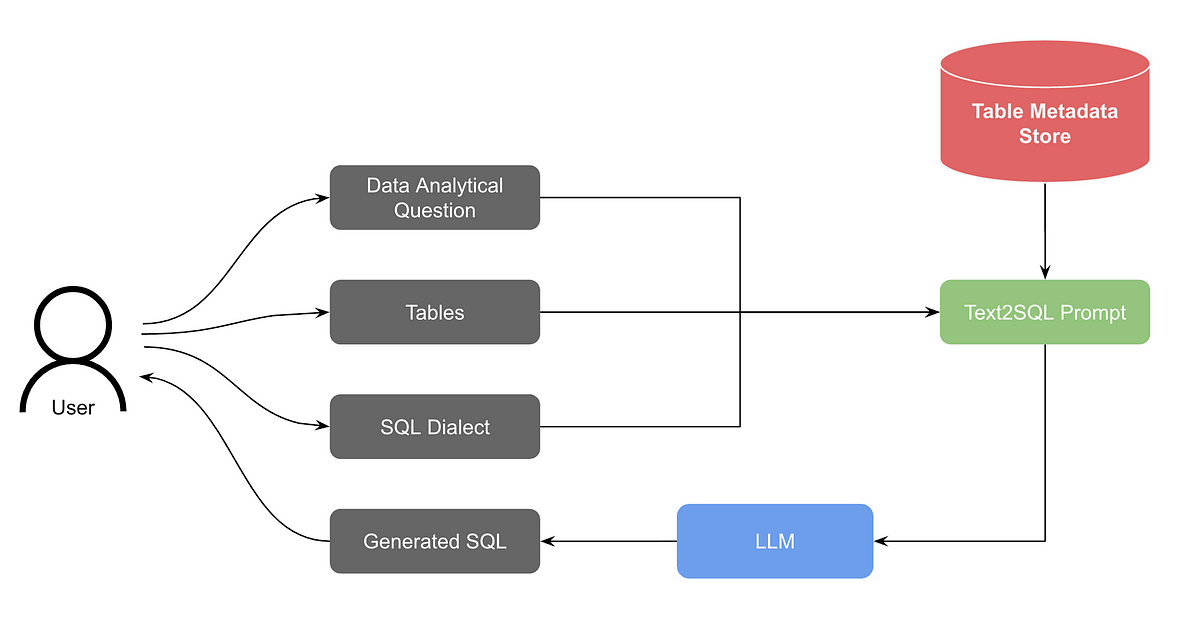
ก่อนจากกัน ทาง Pinterest Engineering เค้าเขียน Blog Post เกี่ยวกับ text-to-sql ไว้ด้วยฮะ ลองตามไปศึกษากันได้
This approach revealed to us that the table metadata generated through our data governance efforts was of significant importance to overall performance
สรุป
มาถึงตรงนี้ วิธีการปรับปรุง Text-to-SQL สรุปคือมีหลายทางให้ลองจริงๆ จะเลือกแบบไหนก็แล้วแต่สะดวก หรือจะมิกซ์แอนด์แมทช์หลายๆ อย่างก็ลองดูครับ
สำคัญสุดคือต้องเข้าใจพื้นฐานปัญหาให้ดีก่อน แล้วค่อยเลือกวิธีให้เหมาะสม พร้อมทดลองไปเรื่อยๆ ถ้าทำถูกวิธี นี่ล่ะคือหนทางไปสู่ Text-to-SQL ที่เทพสุดๆ แน่นอน! ใครลองทำแล้วเป็นไง มาแชร์กันได้นะจ๊ะ ไว้เจอกันรอบหน้า บ๊ายบาย 😉